Appodeal平台的A/B和A/A/B测试货币化指南
公司 Appodeal 制作了一份关于在其平台上进行货币化分割测试的详细教程。

在移动营销中,产品的 A/B 测试是一种广泛采用的实践。它可以快速了解用户对以下内容的反应:
- 新的图形;
- 界面的变化;
- 广告块的位置变动等等。
本文的目的是讲解如何正确地通过分割测试来验证影响应用程序货币化的那些元素的有效性。
本指南以 Appodeal 平台的工作实例为基础,其中包括单独测试广告逻辑和“水流”的设置。
选择测试对象
第一步是决定:
- 要检查的内容(应用程序的哪个方面的变化);
- 计划达到的结果(应该“增长”的是什么)。
这一阶段的成功与否直接影响测试的进行。
因此,在这一阶段:
- 确定测试对象;
- 命名我们希望通过更改测试对象而达到的期望结果;
- 选择监测指标,这些指标在测试对象变化时应该会发生变化(通过它们的新值,可以明确是否达到了期望结果)。
选择关注的指标
通常情况下,我们专注于第七天的累计 ARPU(即第七天的 LTV)。
累计 ARPU 是通过将收入除以受众规模来计算的。重要的是:它的计算仅限于:(a)在同一时间安装应用程序的一组用户内;(b)该指标会随着天数的增加而增长。
根据我们的经验,关注累计 ARPU 是最有效的,因为它的变化可以反映其他所有附加指标的变化。
有时,开发者还会跟踪 ARPDAU,但我们认为这不是最佳选择。因为该指标的增长可能对用户的保留和参与产生负面影响。
示例:进行了测试,观察广告展示频率的增加对应用的影响。结果是 ARPDAU 上升,但前几天的保留率明显下降。
至于为什么要在第七天的结果上进行检查,这并不是特别严格。评估测试有效性的天数是可以调整的,主要取决于应用类型。
我们通常在休闲游戏的货币化上进行 A/B 测试。对我们来说,第七天是最佳选择。到第一周结束时,我们能得到足够的信息,关于新措施对货币化的影响,以及对用户长期留存的影响。
对于超休闲项目,我们当然不会在这个时间点上进行判断。在运作这些项目时,没有必要维持高水平的长期留存。
当然,除了累计 ARPU 以外,还可以使用其他指标来评估有效性:
- 第 N 天的收入;
- ARPDAU;
- 第 N 天的保留率;
- 用户每天在应用中花费的平均时间。
总体而言,选择的指标完全取决于假设及公司期望实现的结果。
还可以选择一个次要指标进行验证。
例如,目标是同时验证两个假设:
- 第一个假设是“广告展示频率影响第七天的 LTV”;
- 第二个假设是“广告展示频率影响第七天的保留率”。
在这种情况下,我们必须准确计算该测试的用户群。因此,我们选择一个需要最多用户的指标进行计算。
顺便提一下,请记得部分指标(例如,累计 ARPU)仅适用于用户群体。
哪些假设值得测试?
验证您的假设是否值得进行 A/B 测试非常简单。如果您认为某些变化将使测量的指标变化不超过 10%,则不值得花时间进行测试。您很难获得可靠且显著的结果。
只有那些假设预计会显著改变被测量指标的情况下,才值得进行测试。
假设可以是多种多样的。有些假设可能仅影响货币化指标(这就是水流测试),但通常情况下,大多数假设检验也会涉及应用的产品指标。
以下是一些我们成功测试过的假设,以验证其对第七天 LTV 的影响:
- 不同频率的全屏广告展示如何影响应用的经济性;
- 不同频率的横幅广告更新如何影响;
- 不同的水流配置和广告网络如何影响;
- 高 CPI 网络如何影响用户的保留和货币化;
- 广告投放的开启/关闭对指标的影响。
测试结果值得信赖吗?
用户可以确定自己可以接受的测试准确性。我们建议设定在 95%。
准确性甚至可以提高到 99%,但这需要将用户组数量增加一倍,从而也延长了测试时间。
降低误差的另一种方法是 A/A/B 测试。接下来,我们会讨论这个。
A+A+B = A/A/B
为了提高假设验证的准确性,Appodeal 进行所谓的 A/A/B 测试。
该测试的核心是添加一个与第一个用户群体相同的额外用户群体。
这种方法可以减少当组显示随机结果时的误差(如果其数量的计算依赖于 95% 的准确性)。
进行三组以上的测试是不必要的,因为这需要太多的时间和用户参与进行测试。
最终选择的测试方法取决于测试时间和指标。
测试参与者的数量应为多少?
这个问题没有通用答案。一切都取决于特定游戏在特定时间段内的情况。
如何判断样本量是否足够?
首先,选择要关注的指标。我们选择第七天的累计 ARPU(这不是二项指标)。
其次,从中介中提取必要的数据。可以使用 Ad 收入归属工具来获得特定期间内用户的收入数据。
第三,根据以下公式计算参与测试的用户数量:
n=( (std**2) * (2*(Za+Zb)**2) ) / m**2
其中:
- Za=1.96 – 针对 p-value=95 %
- Zb=0.8416 – 测试功效为 80 %
- m – 敏感度,表明我们希望捕获的差异的大小
- std – 根据历史数据计算的标准差。
您还可以使用 非二项指标的统计显著性计算器(有免费试用版)。
设置 A/A/B 测试
在假设形成和监测指标选择之后,便可以开始测试。
第一步 — 处理样本
首先,您需要确定参与测试的用户比例。
例如,若希望在 60% 的用户中启动测试,则应在每个样本中形成三个 20% 的用户群体。
对于用户比例的选择,应停留在多少比较合适?
我们建议在所有流量中进行测试(重要的是要理解,控制组也是测试的一部分)。
为什么?
覆盖面越广,越能快速获得结果。
第二步 — 创建用户群体
用户群体是满足某些条件的一部分受众(例如,按性别、年龄、地区或应用程序和 Appodeal SDK 相关的任何其他参数进行选择)。
用户群体用于跟踪不同用户类别的统计数据以及管理这些类别的广告。
创建用户群体应先为其命名。这个名称将在用户群体列表中显示,并出现在该特定用户群体的统计展示中。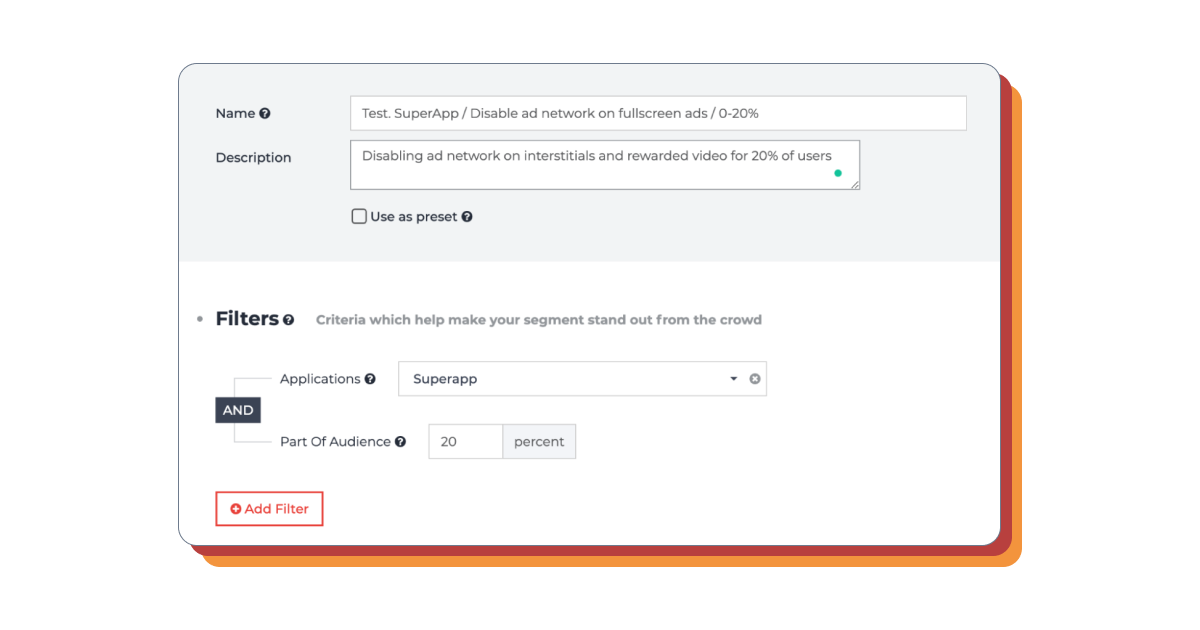
没有广告的用户群体
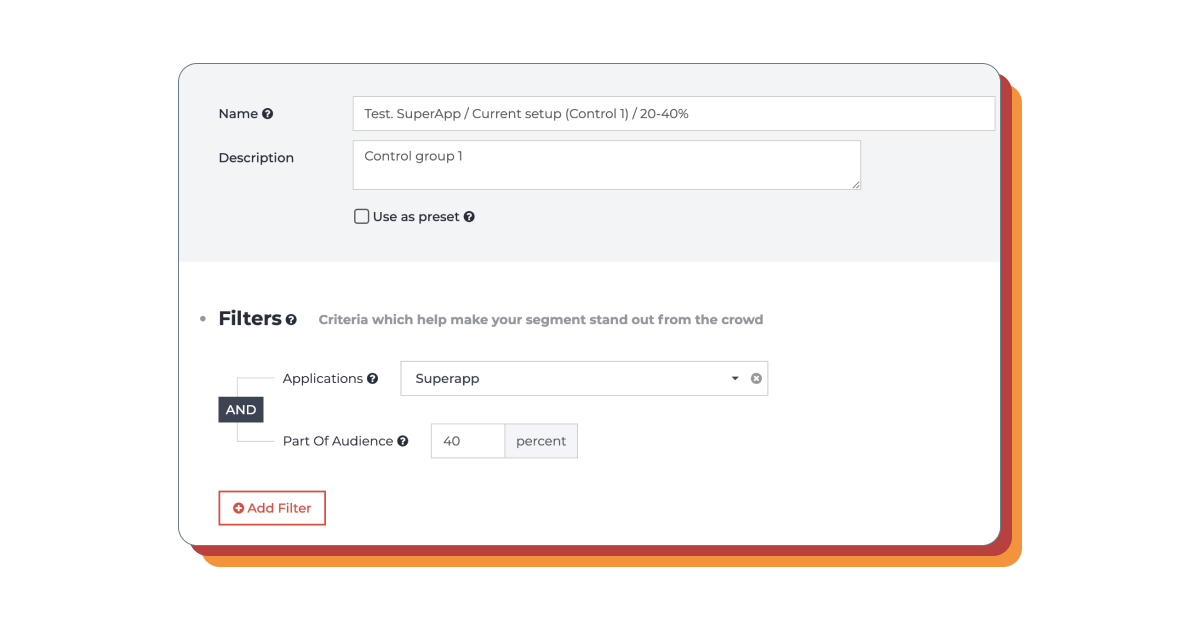
第一控制组
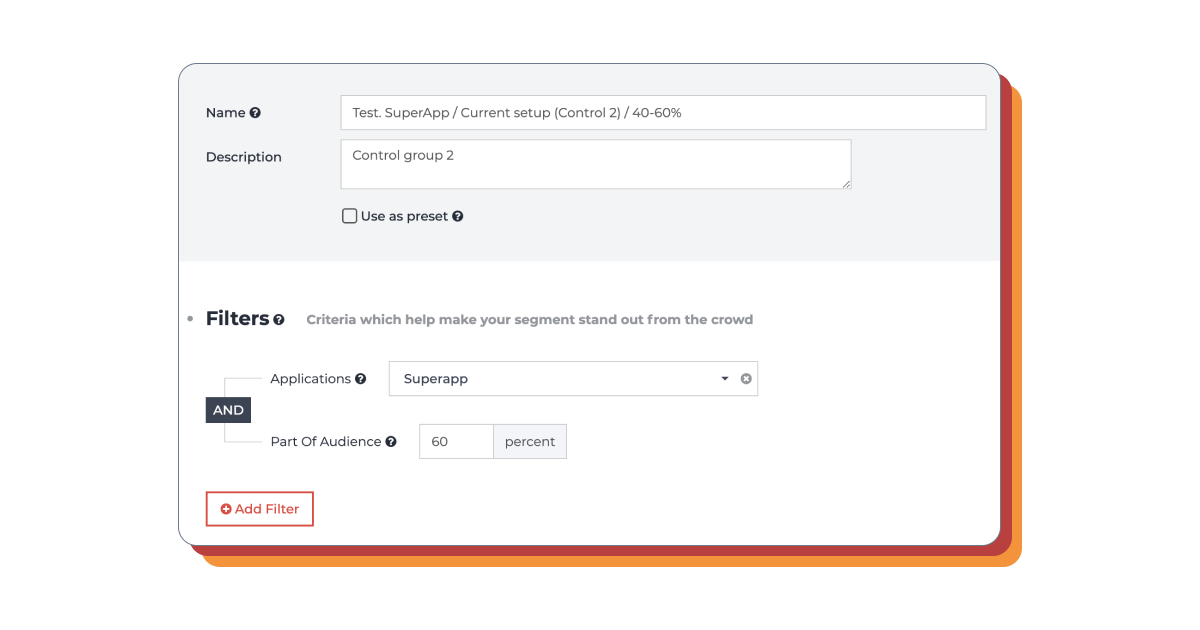
第二控制组
第三步 — 设置
测试用户群体创建后,您需要根据要测试的参数进行设置。
可以根据以下条件分组用户:
- 设备类型;
- 应用程序版本;
- 平均会话持续时间;
- 操作系统版本;
- 进行过应用内购买的用户;
- 进行过 n 次应用内购买的用户;
- 打开过应用的用户;
- 在线用户等等。
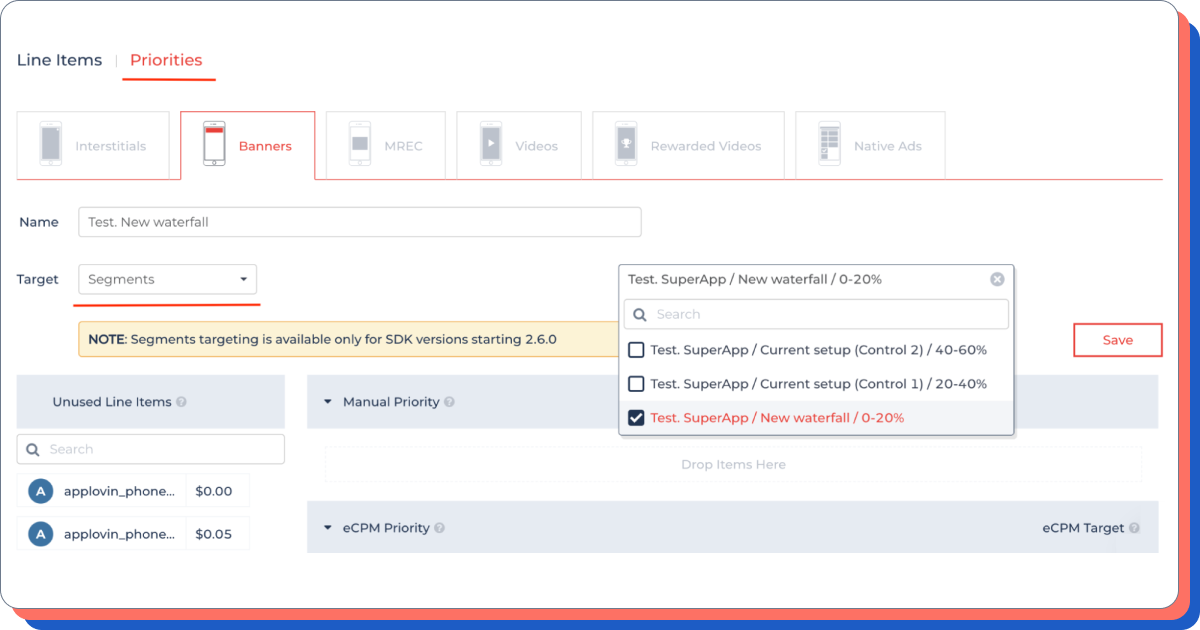
第四步 — 测试新水流
需要执行的步骤:
- 进入 DCC;
- 选择所需的广告类型;
- 创建或复制水流;
- 修改广告块的设置;
- 在测试用户群体上设置水流。
货币化中最常测试的内容是什么?
通常是关于广告网络和广告逻辑的验证。
特定类型广告的广告网络验证
将额外的广告网络纳入货币化系统可能对 ARPU 和保留率产生正面或负面的影响。因此,必须进行测试。
要进行验证,您需要将相关参数添加到测试用户群体中。
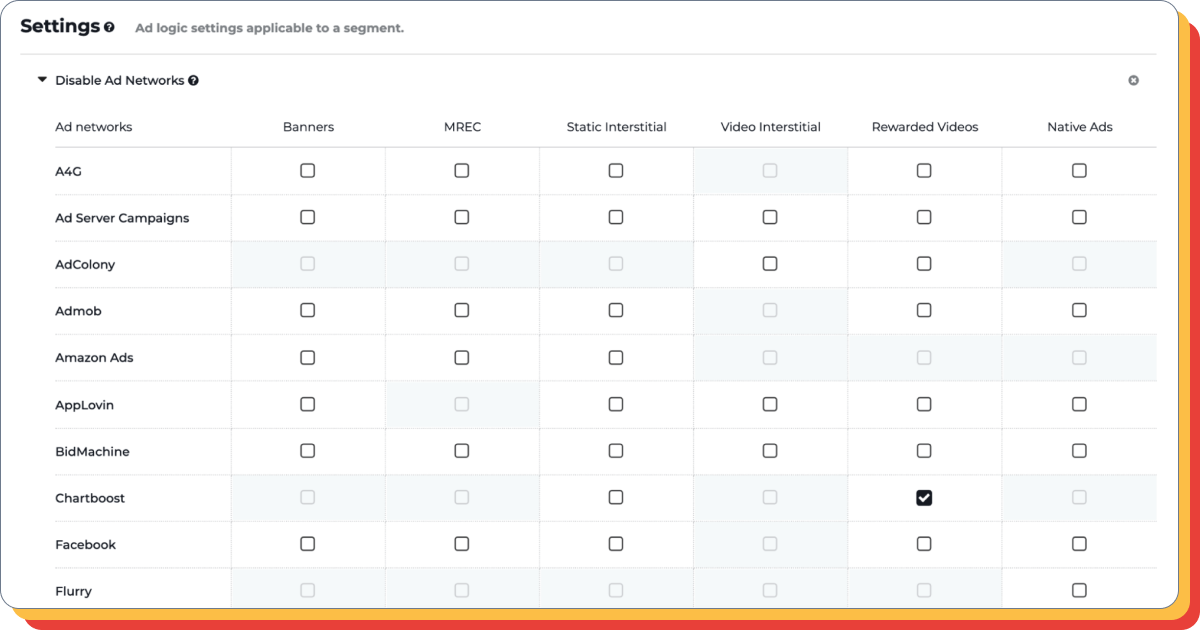
广告逻辑验证
在测试之前,您需要添加相应的展示位置,以匹配您要测试的广告类型,并确保在所有 GEO 中进行相应设置(设置更新频率、广告展示时间、间隔等)。

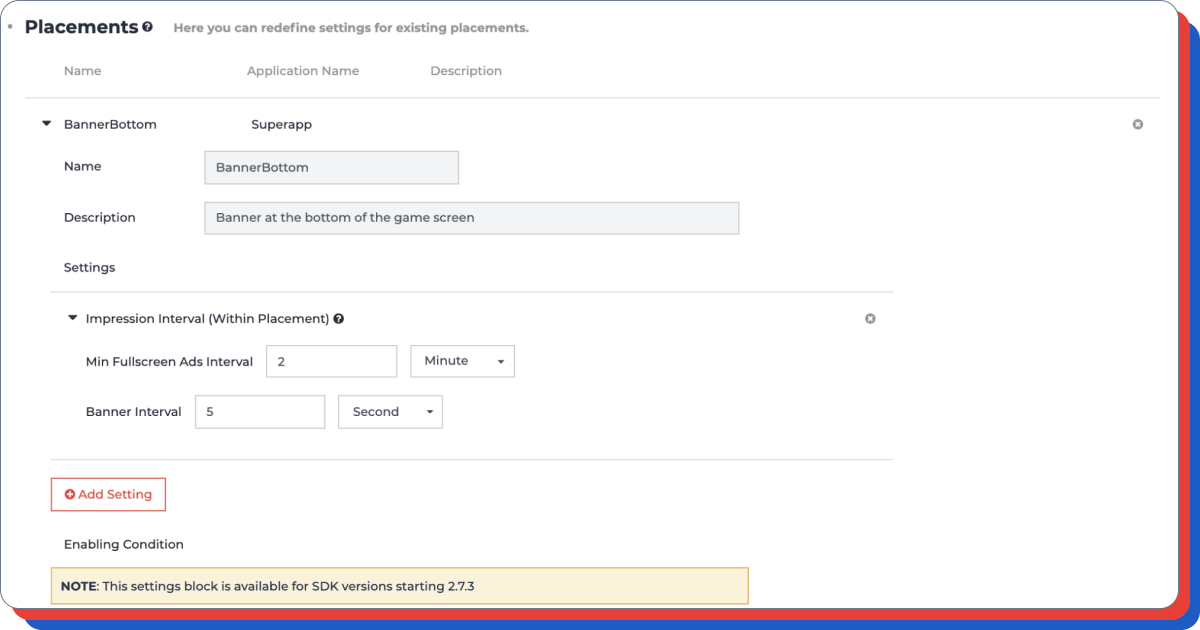
这类测试带来什么结果?
在 Join Blocks 的成功案例中,这是一款经过 Appodeal 商业加速器的游戏,这类实验帮助找到广告展示的最佳间隔。
Join Blocks 的主要市场相差很大,其玩家的行为也大相径庭。因此,广告展示的间隔需要为独立的 CIS、美国和巴西市场单独确定。这样的优化使美国的 ARPU 增加了 20%,而在 CIS 市场则增加了 40%。
重要的是:在开始测试分析之前,请务必等待您需要的日期的用户统计数据完成。由于最后进入测试的用户将稍晚出现,如果您查看的是第七天的指标,则相关统计数据需要一段时间进行积累,以确保结果的正确性。
如何分析 A/A/B 测试的结果
1) 进入 Appodeal 控制面板,创建包含预期指标的报告。记得在过滤器中选择安装日期,以便生成用户细分报告。
2) 分析可以在测试第一周末即可开始,但仅在每个细分群体收集到必要用户量的情况下。测试不应持续太久。否则可能会受到外部因素的影响。
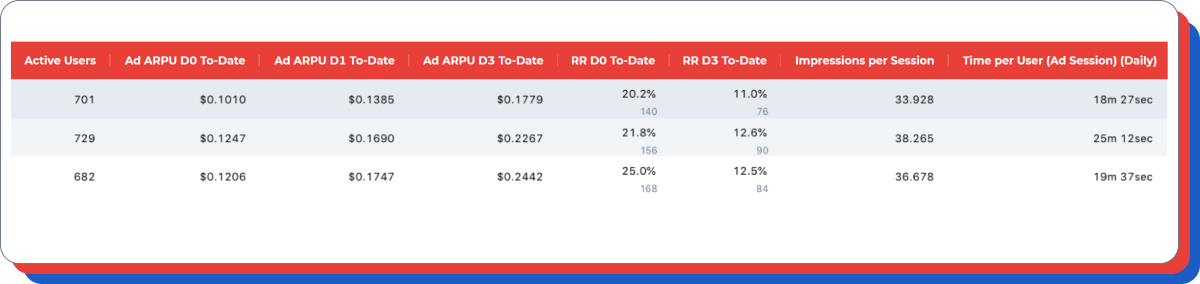
3) 分析您的测试对第七天的累计广告 ARPU 的影响。
额外说明:在上述示例中,我们可以看到测试组的广告 ARPU 比对照组低 20%。
4) 注意保留率和用户每天在游戏中花费的时间。如果假设认为测试应影响保留率,则最好多等一段时间,以便收集更多数据。
额外说明:此时应该特别注意(a)假设预期会对这些指标产生影响,(b) 测试组和对照组的前几天广告 ARPU 接近/相同,而后期广告 ARPU 在某一组中较高。
顺便说一下,在这种情况下——没有足够活跃的用户来做出保留率的决定(在每个对照组中的指标相差颇大)。
5) 对情况做出结论。
在这种情况下,结论是:由于测试组和对照组之间的广告 ARPU 差异很大,而控制组在指标上相对较相似,因此我们可以得出结论,测试组是失败的。实验可以结束。
请记住,成功的测试应在测试组上展示明显变化,理想情况下超过 10%。低于这一变化的测试可视为失败。如果结果不明显,您可以再进行一周的测试,以收集更多数据。
得出结论的条件为:
- 测试组与两个对照组之间的差异超过 10%(如果显示的结果较低,最好重新计算统计显著性);
- 对照组之间的差异少于任何一组与测试组的差异;
- 您收集到了所需数量的用户。
具体的 A/A/B 货币化测试示例
测试回合结束后全屏广告的间隔
假设:增加广告展示频率将导致收入增加,但不会显著影响其他重要指标。
对照组:默认广告展示间隔为两分钟。
测试组:无默认间隔(广告展现更频繁)。

结果:在测试组,主要指标(广告 ARPU D7)比对照组高出 10-15%。同时,附加指标之间没有显著差异。
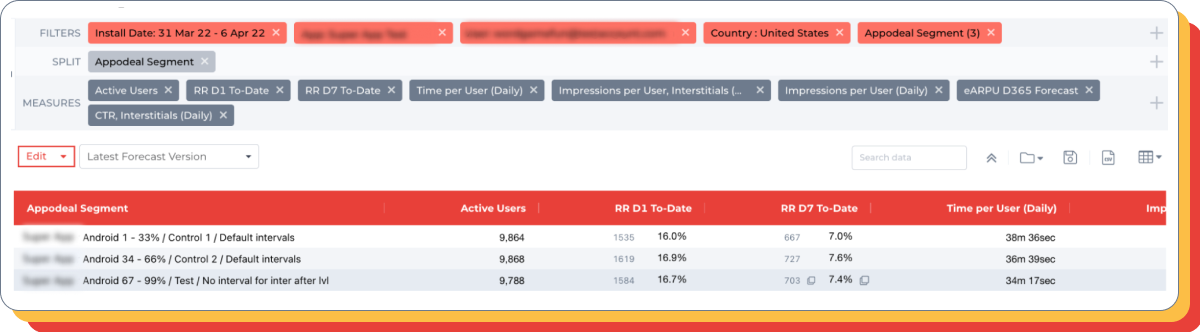
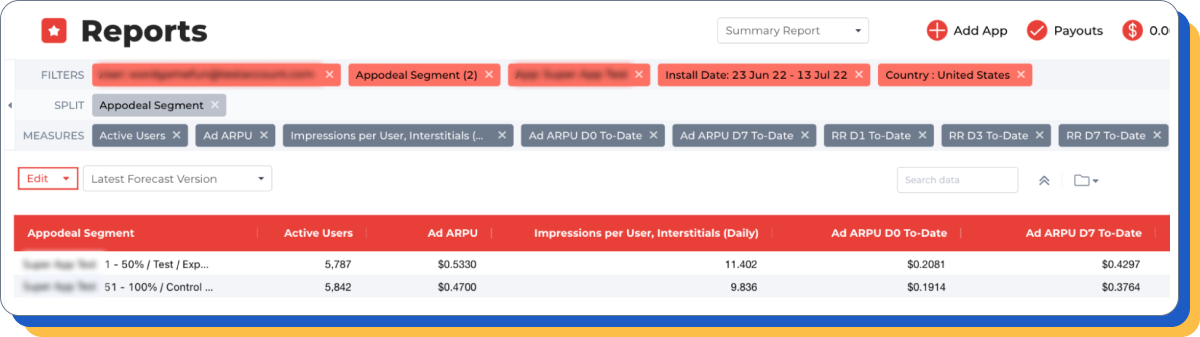
水流配置测试
假设:在删除低价广告位的情况下,添加额外的广告位将提升第七天的 ARPU。
对照组:当前模板(默认设置)。
测试组:添加了以下额外广告位:
- + Admob 25, 35, 45, 60;
- + Notsy 40, 50;
- — Admob 0(所有价格)。
请注意:Appodeal 限制了在 Admob 中调用广告位(每次展示最多允许三次调用)。
在其他中介服务中没有这样的限制。但是,如果在水流中使用超过三次调用,Admob 可能会进行降权。
结果:添加额外广告位对第七天的 ARPU 产生积极效果(+15%)。同时,用户每人观看的广告展示数和占用率均有所增加(即使是在删除低价广告位的情况下)。
为 zero-IDFA 用户(不愿意分享个人数据的用户)优化水流
假设:专注于低流量的广告将提高不愿意分享个人信息的用户群体的收入。
对照组:默认设置。
测试组:删除了许多填充率低的高流量广告位。并添加了更多填充率较高的低流量广告位。
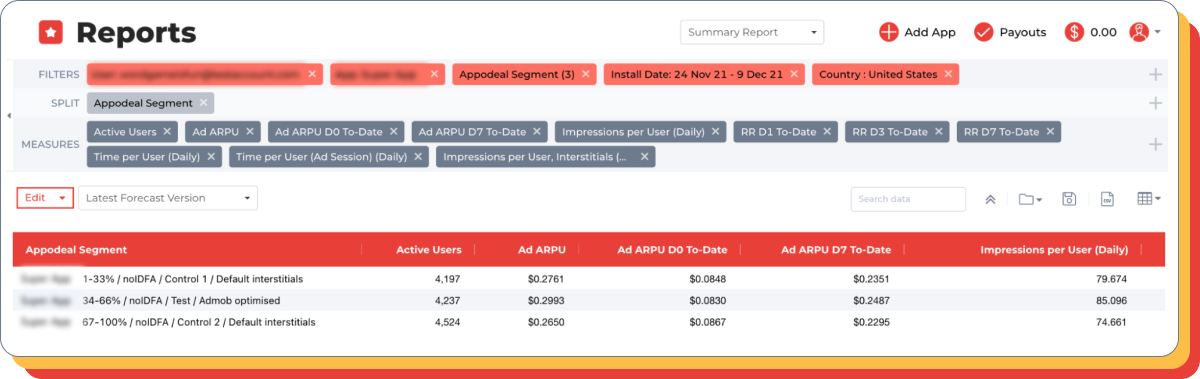
因为对于不提供个人数据的用户而言,通常只有较便宜的广告可用,所以针对价格阈值进行水流优化在应用中取得了良好的结果。
广告填充率上升,用户每人观看的广告量增加,最终使得 ARPU 增加了大约 8-10%。