如何在UI设计中使用神经网络:Playkot艺术家的经验
塔季扬娜·米罗诺娃,Playkot公司的2D艺术家,分享了在为项目春谷制作图标时使用Midjourney和Stable Diffusion的经验。

春谷

塔季扬娜·米罗诺娃
一切始于公司层面的一个问题:如何在不降低质量的情况下,减少当前任务的时间。我们中的许多人之前已经以纯粹的热情探索了神经网络,但为了了解是否可以将AI融入到流程中,需要一种更系统的方法。目前,Playkot几乎所有的团队都在尝试使用神经网络来完成各自的任务,我们在Slack的主题聊天中互相分享经验,当有人有小的突破时,我们就会采纳好的解决方案。我将讲述我们在UI团队针对春谷项目所尝试的内容。
Midjourney:寻找黄金,却发现了铜
我在今年年初开始积极研究神经网络。花了三到四天的时间只是学习工具:有哪些技术和方法,如何理解技术方面的问题。
一开始,我尝试了Midjourney,作为最便宜的选择——我们已经有了一个企业账户用于实验。很快我意识到,使用它来节省创建图标的时间是行不通的:在我当时测试的第四版本中,图片质量令人堪忧。新发布的第五版本质量已经大大提高,但对于我们的任务,结果仍然需要进行重大修改。最大的问题在于——神经网络无法捕捉到所需的风格。简单来说,Midjourney是加载了整个互联网的数据,所以它生成的结果非常不可预测,而且无法针对特定风格进行培训。
尽管如此,事实证明,Midjourney是一个不错的辅助工具,用于生成单个元素或概念。如果需要传达一个想法,找出一种形式——它可以胜任这项工作。

例如,我需要做一个装饰品,浮雕。我花了时间生成了几个选项,但发现没有一个适合我——在3D中构建所有元素更简单。但浮雕上的肖像看起来相当不错:风格上没有太大偏差,没有两个鼻子或歪嘴,为什么不用呢?
在3D程序中,有一个叫做位移贴图(displacement map)的工具——它能在物体的亮面添加高峰,在暗面添加凹陷。我迅速从Midjourney中裁剪了浮雕,给它覆盖上自己的材质,我无需手动绘制肖像。用在图标上的时间与我原本计划的相同,但最终浮雕的图像看起来更有趣,更自然。
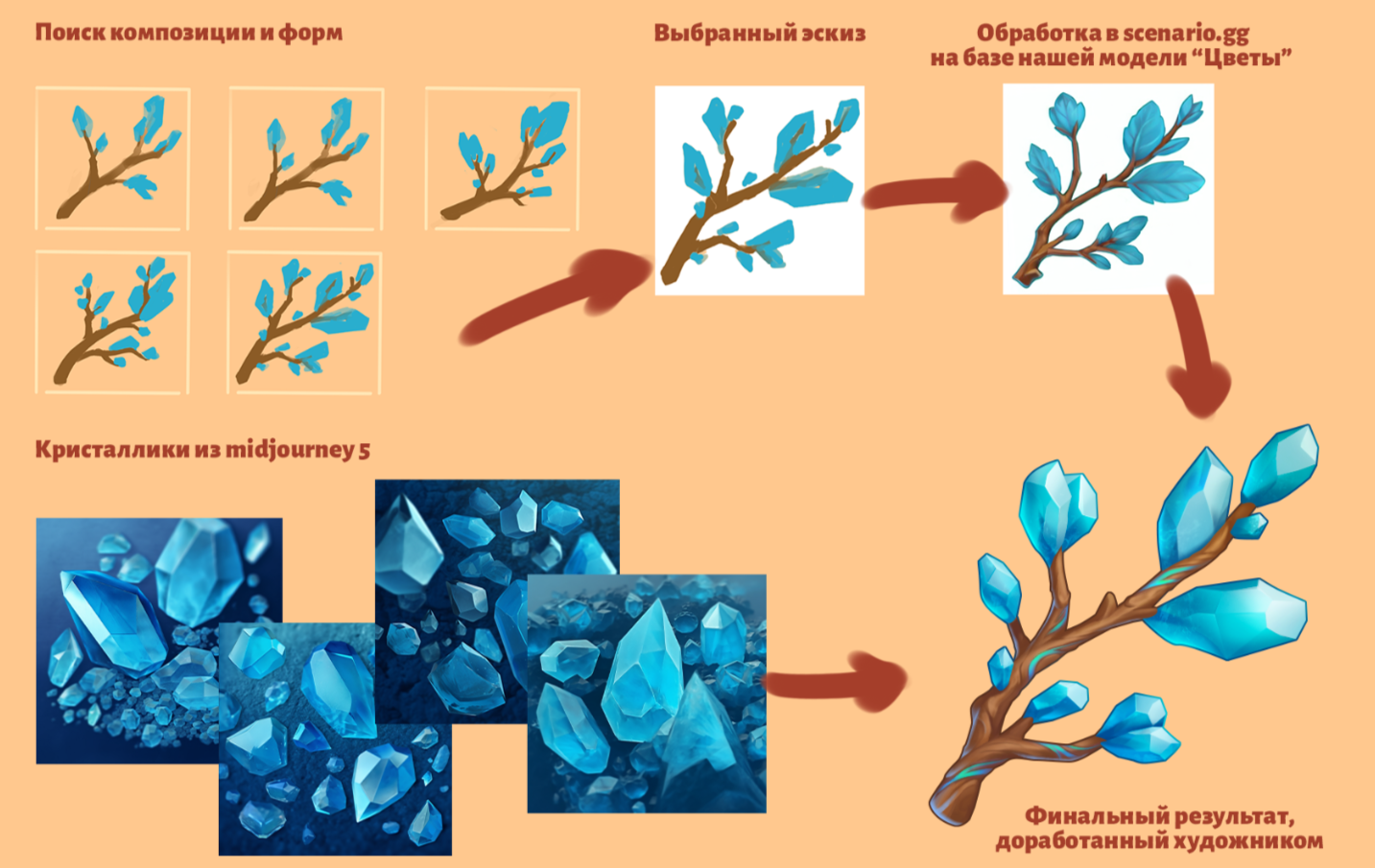
还有一个例子:我需要做一个带有水晶的枝条。思考每个水晶应该是什么样子相当耗时。我给Midjourney一个示例,它生成了一堆水晶的散落效果。然后,我选择了一个最符合我的期望的生成版本,添加了所需的seed(即该生成的变量),并迅速得到了足够的图形素材,最终用于图标。
Stable Diffusion:假设得到了证实
接下来,我开始了对Stable Diffusion的实验。它允许使用已创建的模型作为基础,添加自己的图像,并在此数据集上进行训练。到这个时候,我们项目中已积累了很多适合的风格图标,可以用来制作数据集。
在Stable Diffusion中有几种训练方法:通过Dreambooth扩展、Hypernetwork和LoRA。最初我计划测试每种方法,看看哪种能工作。我们立即排除了LoRA——它更适合人脸和肖像。而Dreambooth扩展表现得很好。
训练模型是一个风险较高的尝试。开始时可能会有一种误导的感觉,认为你一次成功训练后就能收获成果。但当你开始理解需要考虑多少细节……如果你发现结果不理想,就得从头再来。几乎所有神经网络对显卡的要求都很高,如果你的电脑显存不足——这意味着需要重新训练还有三个小时。最终,任何小错误都会延长过程,并且没有任何保证能够达到令人满意的结果。
我记得有一次,我让神经网络进行训练,然后上床睡觉。我想,设个闹钟,等我起来再检查结果。凌晨三点醒来,发现她生成了一束相当不错的郁金香。我心想:“哦哦哦!终于有一些结果了!”
这三张郁金香的图片证明了这是值得的:

当我意识到Stable Diffusion有潜力时,需要解决技术流程的问题。电脑的性能是主要的障碍,并不是我们团队每个人在这方面的能力都相同。通过其他公司的同事的经验,我们了解到,工作的方法是 выделить 单独计算机做服务器,所有生成过程通过这个服务器进行。
与此同时,我们还探索了其他AI爱好者的各种窍门:查看了大量教程,寻找其他合适的模型,最终找到另一个解决方案:一个基于Stable Diffusion、专注于游戏资产的服务——Scenario.gg。拥有更强技术能力的服务器解决了我们的计算能力问题,还有一个意外的好处:在Stable Diffusion中,未经过培训的用户,第一次接触机器学习问题时,常常会感到无从下手,但在网站上的界面直观明了,已经针对我们的需求进行了优化。用户可以选择要训练神经网络进行概念艺术、插图或道具生成。
我们的成果
在其他服务器上,流程加快了,我们终于开始获得更稳定的结果。最佳的方法是图像到图像(image-to-image),当你加载原图时,神经网络会根据模型所训练的风格进行处理。我将通过具体任务的例子告诉你,神经网络是如何帮助我们的。
奇怪的是,制作图标中最复杂的是各种有机形状:植物、水果和蔬菜、食物和花卉。乍一看,花花草草有什么好画的呢?但有机形状需要花费很多时间。而在这方面,神经网络表现得很好。
在我的一个任务中,我需要绘制一个婚礼花束。我之前已经收集了数据集,包括我们的花卉图标:

通过图像到图像方法,我将婚束参考图传给神经网络,让它分析、处理并与我们的风格结合:

我设置了最大生成次数——一次16个。当我处理其他任务时,它已经为我生成了大量的选项。其中一些结果相当不错:在形状和质量上都令人满意,在颜色和渲染上也不错。这是我选出的最佳结果:

如你所见,花束上的彩带有些特殊,但这可以迅速手动修正。最终经过调整后,变成了这个花束:
![]()
目标达成——通过这个任务,我节省了近50%的时间。如果手动绘制这样一个花束需要八到十个小时,但借助神经网络,只需大约30到40分钟就能生成图标,挑选最佳,再做小幅修改,大约四个小时能完成,如果不算一个小时用于构建数据集。
或者,看看这个花冠,这是一个紧急任务,我在四个小时内完成——在处理其他任务时生成了选项:

免责声明:这并不会在任何对象上有效。首先,巨大的优势在于,我们积累了一个不错的、由自己的花卉图标组成的数据集,种类丰富,渲染和形状良好,并且风格统一。其次,Stable Diffusion的基础模型中可能已经包含了大量的花卉图像。简单来说,在这个花束中,我们结合了所有最好的一切。
食物也是Stable Diffusion的另一个成功主题。以汉堡图标的任务为例。一开始,我设置了参数,结果非常奇怪——看看截图中的玉米盘子:

但图像到图像方法效果很好:我找了一张合适的照片,迅速处理后,神经网络将参考图与我们的风格结合:


我挑选了最成功的生成结果。显然,肉饼的外观非常奇怪,芝麻种子也太多了。况且游戏设计师的要求是素食汉堡——在我们的春谷中,理念是我们不杀动物,实际上不捕鱼,不吃肉。我手动修正了这些内容,使图标不那么“嘈杂”,但我仍然节省了一个半到两个小时。最终的版本如下:
![]()
另一个成功的例子是橙色蛋糕。我是基于我们的烘焙图标制作的数据集:

这是我从模型中得到的结果:

这个经过修正的蛋糕将出现在游戏中:
![]()
结合“Stable Diffusion + 便捷服务与强大服务器 + 图像到图像方法”,如果提前做好准备工作:细心收集数据集,并花时间进行训练,将为UI团队节省大量时间。举个例子,假设我被要求制作一个香蕉串的图标。我们已经有不错的数据集——项目中有很多水果图标。根据适当的参考,神经网络给了我一个出色的草图:在颜色上非常契合,也有纹理和不规则的瑕疵,以及香蕉的顶部是绿色的……有地方可以修改,但这不需要太多时间。
唯一的问题是,出现了版权问题。如果你使用了一个可以识别的库存构图作为参考,必须非常仔细地检查许可证,确保允许使用该图像,并寻找具有免费许可的Creative Commons选项。

这些樱桃也很好的符合我们的风格,修正的工作会很少。但很容易看出它们源自库存照片——几乎是“一模一样”。在这种情况下,艺术家应该怎么做?拼贴,变形,看看可以去掉哪些元素,转化它以获得不同的结果,这同样需要额外的时间。
合法性的问题基本上是一个巨大的、尚未被充分研究的领域。例如,在Midjourney等完全向任何观察者开放的神经网络中生成的所有作品——这些东西不属于任何版权。因此,简单来说,从法律角度来看,我现在可以进入Midjourney,将任何生成图打印在T恤上出售,或者将其放入游戏。而任何人都可能发现这生成作品的来源,通过关键词找到,并将同样的插图放入他们的游戏,那么谁能被认为是对的呢?很难预测这个领域将如何发展,这也是一个潜在的风险。
结果更差的情况
我们越是远离有机形状,结果就越糟。Stable Diffusion很难让人们正确构建直线和形状,因此我还未能在所有需要明确构建的对象上获得好的结果。
我们每个人都见过无数次瓶子的样子,并且任何畸变都会被人的眼睛瞬间察觉。尤其是在图标中,一个物体嵌入方框;如果瓶子是歪的,大家都会注意到它的歪斜。
在下面的截图中,我用紫色勾选了那些我可以在工作中使用的部分,但这仅仅是所有生成图中的三张。浪费时间而得不到结果的几率正在上升,因为反正结果还需要在Photoshop中纠正。用形状重绘这瓶子会更简单,或者按我们常用的流程在3D中建模。
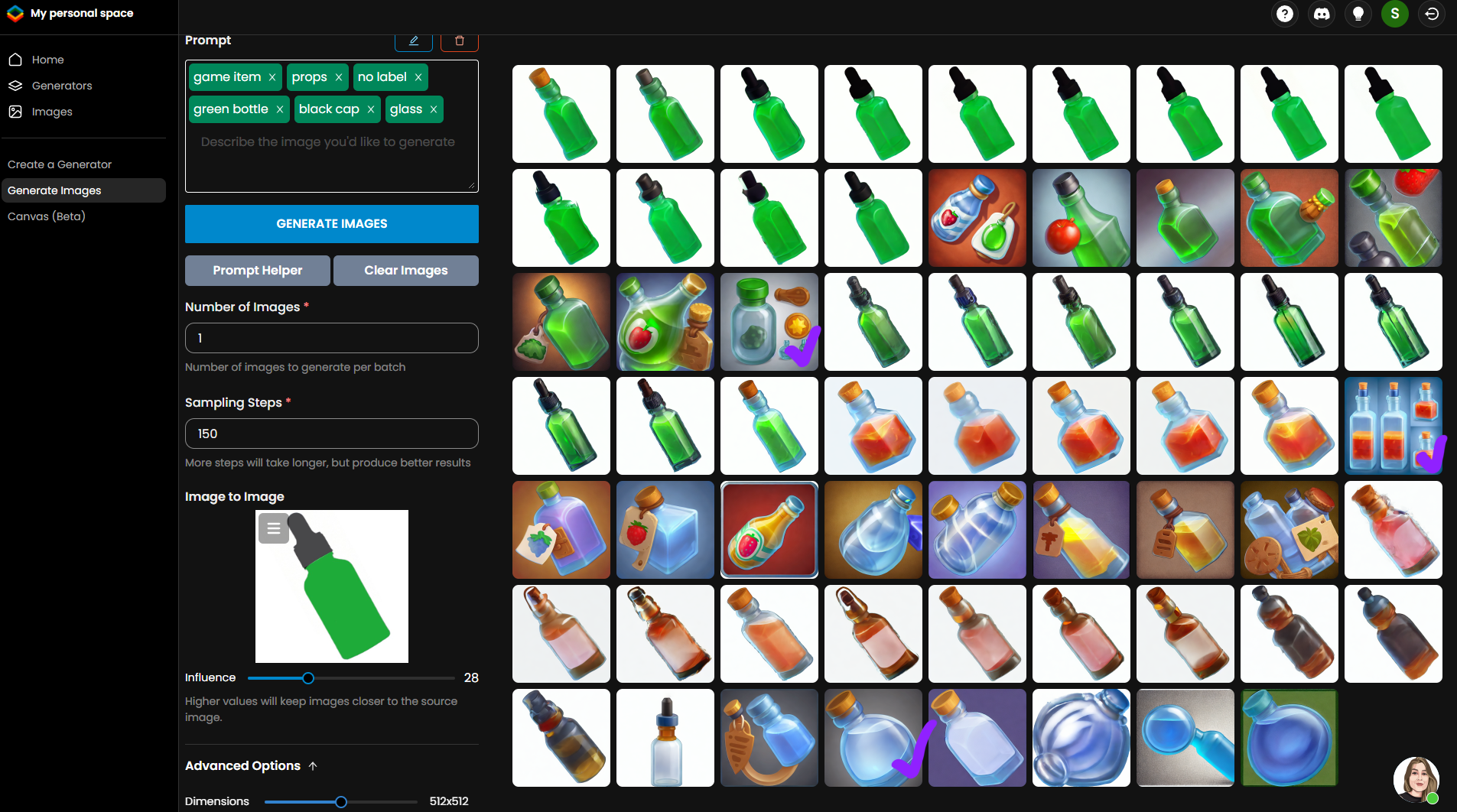
神经网络在重复方面表现得很好。每次它都会取出你加载的那些元素,如果某个特定形状的瓶子用过一次,它便会继续生成那样的瓶子,而不会给出任何本质上的新东西。
另一个困难是向神经网络解释它看到的东西以及如何工作。存在多种学习方式,但最实用的是让它分析上传的图片并为每个图片创建文本描述。训练人员可以进入该文本文件并检查描述。有时它会犯错或根本不理解自己所见。例如,写着:“一个绿色瓶子,木塞,上面装有液体”,但瓶子实际上是透明的。如果这样的情况被漏掉,那么每次你让它生成一个绿色瓶子时,它结果都是透明的,不论你多么用力去要求。每个描述都可以手动检查,但如果你有一百张这样的图片,微调的成本就会非常高。
我再给你一个在大型数据集上失败生成的例子:可以发现,有时结果符合风格,但我完全无法理解里面画了什么。尽管有时我能认出神经网络获取某些元素的来源。

如何为图标组建正确的数据集并开始使用
在实验过程中,我分享了一些经验教训:
- 不要给神经网络输入半透明的图像,否则它会用可怕的伪影填充这些区域,而图像的半透明背景仍然不会生成。
- 在中性白色背景上的对象上训练神经网络——这样可以增加在Photoshop中修剪对象时不必痛苦事后处理的机会。
- 找到一个平衡:数据集不能太小,也不能太大。根据我的经验,任何在7到8张图像的最小会上进行训练的模型,都表现得很差。而在大型各类数据集上,结果也会明显下降。
- 为了生成图标,最好根据实体分割数据集。即瓶子分开,水果分开,钥匙分开。
- 尽可能在训练神经网络时检查其文本描述,看它是否正确识别了在数据集中显示的内容。
总而言之,我们仍然很远不能让神经网络完全代替我们工作,但我们可以将其用作另一种工具:除了已经取得不错效果的有机图标外,还可以生成辅助材料、图案、海报、背景及背景部分——所有那些岩石、树木和花朵通常需要耗费大量时间,费力不讨好。以所需的风格生成它们并做拼贴,会更快。
我们还没有将在整团队推广这些方法,现在还没有完全融入到进程中——我们觉得,尚未详细研究所有可能性,就不应着手推进。但我认为神经网络在某种意义上会使艺术家们能够创作出更加复杂的作品。
当我计划一个任务时,我会预估在规定时间内可以完成什么。这就像两个牛仔的流行迷因,一个是经理,另一个是设计师。“你打算花多长时间完成这个任务?”“那我应该花多长时间完成这个任务?”在相同的时间内,我们将能够完成更复杂的事物。这是一个巨大的优势。