F2P游戏的数据分析:计算LTV的三种方法
任何条件下免费游戏中一个最重要的指标是生命周期价值(Lifetime Value,LTV),它是游戏从一个客户那里获取的所有收入的总和。如何计算这个值,数据分析专家伊萨克·罗兹布姆(Isaac Roseboom)在他的文章中进行了详细介绍。同时,我们的朋友们在SoftPressRelease将他的作品翻译成了俄文。

准确计算每次安装的价值是F2P商业规划中最重要的部分。尤其是当每次安装可能花费您1到2美元的时候。因此,许多发行商投入大量资源开发准确的LTV预测方法。这些方法通常属于以下三种方法之一:
- ARPDAU模型
- 交易模型
- 玩家模型
在第一个模型中,收入按天进行预测。在第二个模型中,预测每位玩家的交易数量和交易额。最后,在第三个模型中,使用相同人口统计特征的玩家的历史价值。接下来,我们将详细解释这些模型的计算,并告诉您何时应用某种方法更为合适。
1) ARPDAU建模:简单方法
最常见的方法是使用
LTV =
每次安装的平均天数是通过拟合留存率曲线的幂函数来计算的,即:
R ∝ d — α
有几种方法可以拟合α,但最简单的方式是使用回归来拟合log (R) ∝ log (d)。不建议使用线性回归,因为log (R) 的误差值不呈正态分布。
一旦确定了幂函数的斜率,<游戏时长总天数> 在d = D天(安装后天数)时通过留存的幂函数的积分来计算,即:
<游戏时长总天数> =
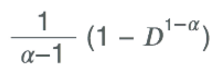
这个值可以与ARPDAU一起使用来获得LTV。
作为一个示例,假设ARPDAU = $0.1,而我们在D1到D7的留存率分别为35%、28%、25%、21%、18%、15%和13%。通过拟合幂函数得到α=1.3,这又导致<游戏时长总天数> = 2.77天,当D = 365天时。
这意味着我们的LTV = $0.28。
这种估算LTV的方法无疑是最简单的。然而,由于这种简单性,我们也不得不忍受一些缺点。首先,在长期游戏中,ARPDAU将基于已经存在的玩家,而这些玩家可能更倾向于购买,跟您试图预测的群体的行为不同。再者,所有玩家的留存率通常不及付费玩家。因此,这最终意味着使用该方法进行预测的典型误差在30-40%之间,适用于500个玩家的群体。
2) 交易建模:关注付费者
更复杂的方法涉及建模玩家在其“生命周期”中进行的交易数量。
可以构建一个统计模型,该模型将给出P (T|D),即在安装后的第D天,玩家进行交易的概率。如果Nt是第t天观察到的交易数量,则在某个未来的第D天,预计的交易数量为:
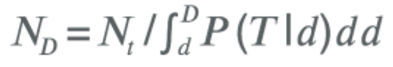
付费者的转化率可以类似建模,即P (C|D) – 玩家在第D天成为付费者的概率。
这些概率分布可以通过不同的“长尾”分布来描述。不同类型的游戏适用不同的分布。例如,对于PC游戏,幂函数通常适用,而对于社交赌场游戏,则适合使用伽马分布。
这些模型可以使用数值方法构建。R和Python中提供的库使得这一过程变得轻松。在R中,函数fitdistr允许通过数值最大似然参数搜索将概率分布集与数据集进行匹配。在获得最佳模型的分布后,LTV在第D天的计算可以表示为

其中
这一方法的优势在于它建模了生成LTV的玩家的行为,即付费玩家。准确建模转化率对于在后期阶段转化大量玩家的游戏至关重要,例如MMO游戏。交易建模对于每位付费玩家交易数量高的游戏来说尤其重要,也就是说,对于休闲益智游戏或没有高级货币的其他游戏。
尽管此方法比第一个方法提供了更高的准确性,但它仍基于对群体进行工作的假设,因此需要合适的玩家数量来实现准确性,即无法为个别用户提供良好的LTV计算方法。
如果不考虑这一限制,假设使用了合适的分布且经过测试,这种类型的模型通常能达到约20%的准确性(适用于500玩家的群体)。
3) 玩家建模:个体LTV的预测
理想的情况是能够对每个玩家的LTV进行可靠的评估。这不仅可以帮助您做出针对收购和盈利能力的决策,还可以改变游戏如何与玩家互动,例如,低LTV的玩家将接收到更多广告,而高LTV的玩家则会获得VIP优惠。
为了预测玩家级别的LTV,需要使用更多详细的玩家信息,包括人口统计和行为数据。可以使用的指标类型示例包括:国家、设备类型、游戏会话频率、成功等级、内购好友数量等。
利用不同时段的数据集,这些指标可以用于构建回归模型来计算LTV。根据基础指标的分布,可以使用单一模型,也可以将玩家分成具有不同特征的多个组,例如,可能需要为iOS和Android上的玩家使用完全不同的回归模型。
构建的模型可以用于预测个别玩家的LTV。整个群体的LTV可以通过对个体预测的LTV取平均来计算。
所有这些功能都可通过R或Python中的统计包实现。在R中,可以使用kmeans或hclust进行数据分割,使用glm进行回归。
这种方法的明显优点是可以获得个体LTV。然而,为了确保结果的可靠性,需要在较长时间内收集广泛的、相关的数据。这意味着该方法不能在新游戏首发或重大更新后使用。
构建准确模型
尽管所有三种LTV模型都能产生良好的结果,但决定采用哪种模型取决于您的游戏所处的情境。如果您有少量玩家且“生命周期”相对较短(例如,几周),那么最好选择方法1)。
如果您有大量玩家,并且预期在“生命周期”和消费模式方面会有很大的差异,那么需要使用方法2)。
最后,如果您有一款表现良好的游戏,并且版本稳定且有忠实玩家,那么方法3)可能会提供显著的优势。
无论如何,最重要的是在过去一定时间内对您的模型进行测试,以验证其准确性并理解其限制。最后需要指出的是,在样本过小(例如少于100个玩家)时,绝对无法构建可信的LTV模型。在这种情况下,LTV = 4 x ARPDAU的近似方法将比任何统计方法都更能够帮助您更好地理解情况。
来源: deltaDNA
翻译: SoftPressRelease