Как использовать нейросети в работе над UI: опыт художницы из Playkot
Татьяна Миронова, 2D-художница компании Playkot, поделилась опытом использования Midjourney и Stable Diffusion при работе над иконками для проекта Spring Valley.

Spring Valley

Татьяна Миронова
Все началось с вопроса на уровне компании: как тратить меньше времени на текущие задачи и при этом не просесть в качестве. Многие из нас до этого уже исследовали нейросети на чистом энтузиазме, но чтобы понять, можем ли мы встроить AI в процессы, нужен был более системный подход. Сейчас почти все команды в Playkot пробуют использовать нейросети для своих задач, мы делимся друг с другом опытом в тематическом чате в Slack, и когда у кого-то возникают мини-прорывы, подхватываем хорошие решения. Расскажу, что мы попробовали в нашей UI-команде на проекте Spring Valley.
Midjourney: искали золото, а нашли медь
Я начала активно исследовать нейросети в начале этого года. Три-четыре дня ушло просто на изучение инструментов: какие есть технологии и подходы, как разобраться с технической стороной вопроса.
Сначала попробовала Midjourney как самый доступный вариант — у нас уже был корпоративный аккаунт для экспериментов. Довольно быстро я поняла, что сэкономить время на создании иконок она нам не поможет: в четвёртой версии, которую я тогда тестировала, качество картинки оставляло желать лучшего. В свежей пятой версии качество стало намного лучше, но для наших задач результаты все равно требуют серьёзных правок. Самый большой камень преткновения — нейросеть не попадает в нужный стиль. Грубо говоря, в Midjourney загружен весь интернет, поэтому она выдает очень непредсказуемые результаты, а обучить ее под свою стилистику нельзя.
Тем не менее, оказалось, что Midjourney — неплохой вспомогательный инструмент для генерации отдельных элементов или для концептов. Если нужно передать идею, найти для нее какую-то форму — с этим она справляется.

Например, мне нужно было сделать украшение, камею. Я потратила время на генерации и поняла, что ни одна из них мне не подходит — проще построить все в 3D. Но сами портреты на камеях выглядели достойно: особо не выбивались из стилистики, никаких двух носов или кривых ртов, почему бы их не использовать?
В 3D-программах есть возможность использовать инструмент под названием displacement map — он добавляет на объект высоты, где изображение светлое, и впадины — где темное. Я быстро вырезала в Photoshop камею из Midjourney, наложила на нее собственный материал, и мне не пришлось отрисовывать вручную портрет. На иконку было потрачено столько же времени, сколько я и планировала, но в результате изображение камеи получилось интересным, более натуральным.
И еще один пример: мне нужно было сделать ветку с кристаллами. Продумывать, как будет выглядеть каждый из них, довольно долго. Я дала Midjourney пример, она сгенерировала россыпь этих кристаллов. Потом я выбрала генерацию, которая меня больше всего устраивала, добавила в промт нужный seed, то есть переменную той генерации, и быстро получила достаточно графического материала, который в итоге использовала в иконке.
Stable Diffusion: гипотеза, которая подтвердилась
Дальше я начала эксперименты со Stable Diffusion. Она позволяет взять уже созданную модель за основу, добавить свои изображения и обучить на этом массиве данных — он называется датасетом. У нас на проекте к этому времени уже накопилось много хороших иконок в нужном стиле, которые можно было использовать для датасетов.
В Stable Diffusion есть несколько способов обучения: через Dreambooth extension, Hypernetwork, LoRA. Была задумка проверить каждый из них и посмотреть, что из этого будет работать. LoRA мы отмели сразу — он лучше подходит для лиц и портретов. Зато хорошо сработал Dreambooth extension.
Обучение модели — это рисковая затея. На первых порах может сложиться обманчивое ощущение, что сейчас ты один раз удачно ее обучишь, а потом будешь пожинать плоды. Но когда начинаешь понимать, сколько подробностей нужно учесть… Если видишь, что результаты не очень, нужно начинать заново. Почти все нейросетки очень требовательны к видеокартам, и если у тебя мало видеопамяти на компьютере — это еще три часа на переобучение. В итоге любая мелкая ошибка растягивает процесс, и при этом нет никакой гарантии, что результат будет настолько хорош, что сможешь его использовать.
Однажды, помню, я поставила нейросетку обучаться и легла поспать. Думаю, заведу себе будильник, встану и проверю, что получилось. Просыпаюсь в три часа ночи, а она мне сгенерировала нормальный такой букет тюльпанов. Я такая: «О-о-о! Ну наконец-то, хоть какой-то результат!».
Эти три картинки с тюльпанами доказали, что игра стоит свеч:

Когда я поняла, что у Stable Diffusion есть потенциал, нужно было решить проблему с технической стороной процесса. Мощность компьютера — это главный блокер, не у всех в нашей команде в этом плане равные возможности. По опыту коллег из других компаний мы узнали, что рабочий способ — выделить отдельный компьютер под сервер, через который будут идти все генерации.
Параллельно мы перебирали разные лайфхаки от других AI-энтузиастов: пересмотрели огромное количество туториалов, искали другие подходящие модели, но в итоге нашли другое решение: сервис на базе Stable Diffusion, который специализируется на игровых ассетах — Scenario.gg. Сервера с более высокими техническими возможностями решили нашу проблему с мощностями, а еще обнаружился приятный бонус: в Stable Diffusion у неподготовленного пользователя, который раньше не погружался в вопросы машинного обучения, с непривычки глаза на лоб лезут, а на сайте интерфейс интуитивно понятен и уже заточен под наши запросы. Можно выбрать, хочешь ли ты обучить нейросеть концепт-арту, иллюстрации или генерации пропсов.
Что у нас получилось
На чужих серверах процесс пошел быстрее, мы наконец стали получать более стабильные результаты. Лучше всего зашел метод image-to-image, когда ты загружаешь исходную картинку, а нейросеть ее обрабатывает под стилистику, на которой модель обучили. Расскажу на примере конкретных задач, где нейросеть нам помогла.
Как ни странно, самые сложные в производстве иконки — это всякого рода органика: растения, фрукты-овощи, еда, цветы. Казалось бы, ну цветочки и цветочки, что там рисовать? Но на построение органических форм уходит много времени. И как раз здесь нейросеть отлично справилась.
Для одной из моих задач нужно было нарисовать свадебный букет. Я до этого уже собрала датасет из наших иконок с цветами:

С помощью метода image-to-image закинула нейросетке букетик-референс, чтобы она его проанализировала, обработала и совместила с нашим стилем:

Поставила максимальное количество генераций — 16 за один раз. Пока я занималась другой задачей, она сгенерировала мне огромное количество вариантов. Часть из них оказалась неплохой: устраивала и по форме и массам, и по цветам, и по рендеру. Это лучшие результаты, которые я отобрала:

Как видите, ленточки на букетах получаются своеобразными, но как раз это можно быстро поправить вручную. В итоге в игру после правок ушел вот такой букет:
![]()
Цель выполнена — на этой задаче я сэкономила почти 50% времени. Вручную я бы рисовала такой букет часов восемь-десять, а с нейросетью можно минут за 30-40 нагенерировать иконок, отобрать лучшие, внести минимальные правки и уложиться примерно в четыре часа, если не учитывать еще час на составление датасета.
Или вот цветочная корона, очень срочная задача, с которой я справилась за четыре часа — генерировала варианты в нейронке, пока занималась другой задачей:

Дисклеймер: это не будет так хорошо работать для любых объектов. Во-первых, огромный плюс — что у нас собрался хороший датасет из собственных иконок с цветами, разнообразных, с хорошим рендером и формами, в едином стиле. А во-вторых, в базовую модель Stable Diffusion, скорее всего, уже залито огромное количество цветов. Грубо говоря, в этом букете мы совместили все самое лучшее.
Еда — еще одна удачная тема для Stable Diffusion. Возьмем задачу с иконкой бургера. Сначала я задала параметры промптом, и результаты были максимально странные — посмотрите на тарелки с кукурузой на скриншоте:

Но метод image-to-image сработал хорошо: я нашла подходящую фотографию, быстро обработала ее, и нейросеть совместила референс со стилистикой:


Я отобрала наиболее удачные результаты генерации. Понятное дело, видно, что и котлеты здесь очень странные, и кунжутных зерен слишком много. Да и запрос от гейм-дизайнеров был на вегетарианский бургер — у нас в Spring Valley, такая концепция, что мы не убиваем животных, по-настоящему не ловим рыбу и мяса не едим. Я правила все это и делала иконку менее «шумной» вручную, но часа полтора-два времени все равно сэкономила. В игру пошел такой финальный вариант:
![]()
Еще один удачный пример — апельсиновый кекс. Такой датасет я сделала на основе наших иконок с выпечкой:

Такие результаты получила от модели:

Такой кекс после правок пойдёт в игру:
![]()
Связка «Stable Diffusion + удобный сервис с мощными серверами + метод image-to-image» сэкономит UI-команде массу времени, если заранее подготовить почву: тщательно собрать датасеты и потратить время на обучение. Представим, например, что мне заказали иконку с гроздью бананов. У нас уже есть приличный датасет — на проекте много фруктовых иконок. По правильному референсу нейросеть выдает мне отличный подмалевок: здесь и по цветам хорошее попадание, есть и текстуры, и неровности, и даже верхушка у банана зеленая… Есть что править, но это займет не так много времени.
Единственная проблема — возникает вопрос авторских прав. Если ты используешь как референс узнаваемую стоковую композицию, нужно очень тщательно перепроверять, позволяет ли лицензия использовать это изображение, искать варианты с бесплатной лицензией Creative Commons.

Эти вишни тоже хорошо попали в нашу стилистику, правки здесь были бы минимальные. Но легко увидеть, что они сделаны из стоковой фотографии — тут почти один в один. Что в этом случае делать художнику? Коллажировать, видоизменять, смотреть, какие элементы можно убрать, перевоплощать это, чтобы получить другой результат, и на это тоже нужно дополнительное время.
Легальная сторона вопроса — это в принципе большой и мало изученный пласт. Например, все работы, которые сгенерированы в нейросетях, особенно в полностью открытой для любого зрителя Midjourney, — все эти вещи не являются объектом авторского права. Грубо говоря, с точки зрения закона я могу сейчас зайти в Midjourney и любую генерацию напечатать на футболках для продажи или засунуть ее в игру. А кто-то поймет, где это сгенерировано, найдет ее по ключевым словам и ту же самую иллюстрацию засунет в свою игру, и кто будет прав? Сложно предсказать, как в этой сфере будут развиваться события, и это еще один потенциальный риск.
Что получается хуже
Чем дальше мы отходим от органических форм, тем хуже результаты. Stable Diffusion сложно научить правильно строить прямые формы и линии, поэтому мне пока не удалось добиться приличных результатов для всех предметов, которые требуют четкого построения.
Каждый из нас тысячу раз видел, как выглядит бутылка, и любое искажение человеческий глаз замечает моментально. Тем более, на иконке, где один объект вписан в квадрат, — если бутылка будет кривой, каждый заметит, что она кривая.
На скриншоте ниже я фиолетовыми галочками отметила то, что могла бы использовать в работе, но это всего три картинки из всей массы генераций. Растут шансы, что потратишь время зря и ничего не получится, потому что все равно результат придется выправлять шейпами в Photoshop. Будет проще нарисовать эту бутылку теми же шейпами или смоделировать в 3D по привычному пайплайну.
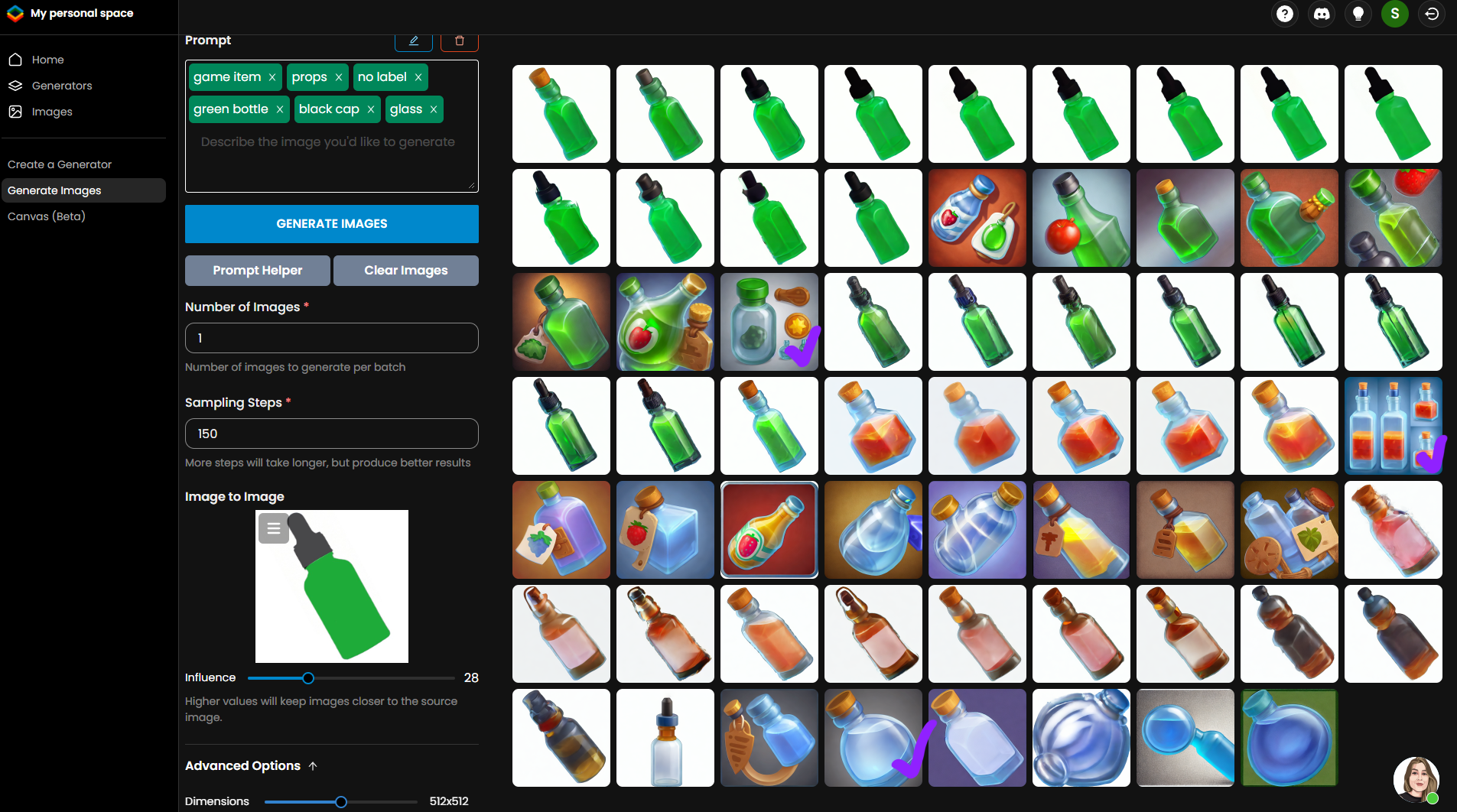
Нейросетка очень хороша в повторении. Она раз за разом берет те элементы, которые ты в нее загрузил, и если упрется один раз в бутылку определенной формы, то так и продолжит ее генерировать и не выдаст ничего принципиально нового.
Еще одна сложность — объяснить нейросети, что именно она видит и как это работает. Существуют разные способы обучения, но наиболее практичный — это когда она анализирует загруженные картинки и создает текстовое описание для каждой. Человек, который ее обучает, может залезть в этот текстовый файл и проверить описание. Иногда она допускает ошибки или совсем не понимает, что видит. Например, написано: “A green bottle with a wooden cork and liquid inside”, а бутылка на самом деле прозрачная. Если такое пропустить, то каждый раз, когда ты будешь просить у нее зеленую бутылку, она тебе будет выдавать прозрачные, хоть ты тресни. Можно проверить каждое описание вручную, но если у тебя сотня таких картинок? Цена тонкой настройки очень высока.
Покажу еще один пример неудачной генерации на большом датасете: здесь можно заметить, что иногда результат попадает в стилистику, но я совсем не могу понять, что там нарисовано. Хотя даже узнаю, откуда нейросеть взяла отдельные элементы.

Как составить правильный датасет для иконок и начать жить
Делюсь уроками, которые мы выучили в процессе экспериментов:
- Не скармливайте нейросетке изображения с полупрозрачностью, иначе она заполнит эти места чудовищными артефактами, а на генерациях полупрозрачного фона все равно не будет.
- Обучайте нейросеть на объектах с нейтральным белым фоном — больше шансов, что потом не придется мучительно вырезать объекты в Photoshop и думать, что быстрее было бы накидать все вручную шейпами в векторе.
- Найдите баланс между слишком маленьким датасетом и слишком большим. По моему опыту, все, что обучалось на минимальных сетах в 7-8 изображений, выходило плохо. На больших разномастных датасетах результаты тоже становятся ощутимо хуже.
- Для генерации иконок лучше разбивать датасеты по сущностям. То есть бутылки отдельно, фрукты отдельно, ключи отдельно.
- Когда обучаете нейросеть, по возможности проверяйте текстовые описания — правильно ли она распознала, что изображено в вашем датасете.
Если подытожить, мы пока очень далеки от момента, когда нейросеть сможет работать за нас, но можем ее использовать как еще один инструмент: помимо органических иконок, которые у нас уже неплохо получаются, можно генерировать вспомогательные материалы, паттерны, плакаты, фоны и части фонов — все эти скалы, деревья, цветочки обычно отнимают много времени, это кропотливая работа. Сгенерировать их в нужной стилистике и коллажировать — гораздо быстрее.
Мы пока не масштабировали эти подходы на всю команду, это на 100% не вошло в процессы, — есть ощущение, что рано этим заниматься, пока мы не изучили все возможности. Но думаю, что нейросети позволят художникам делать в некотором смысле более комплексные вещи.
Когда я планирую задачу, я прикидываю, что могу сделать за предложенный срок. Тут как в меме с двумя ковбоями, где один из них менеджер, а другой дизайнер. «Сколько вы потратите на эту задачу?» – «А сколько мне надо потратить на эту задачу?». За то же количество времени мы сможем делать более сложные вещи. И это большой плюс.