Technical aspects of game design. How to structure game content data for the engine
How to record all game content in the format that the engine will accept, — said Konstantin Sakhnov, founder of the Vengeance Games studio and scientific director of the Game Project Management program at the HSE.


Konstantin Sakhnov
One of the most common and difficult tasks faced by both beginners and experienced game designers is the description of a large amount of content to transfer its parameters to the engine.
In this article, I’ll look at the whole process using the example of a game I’m currently working on. This is a planet terraforming simulator with a consistent set of missions and a focus on the plot.
Key mechanics of the future game:
- construction of buildings on the planet;
- terraforming the planet;
- the development of the talent tree.
The game will have a large number of buildings. Each has a set of conditions, functions and parameters.
To understand: resources are needed for the construction of any building. The required number and type of resources for each building is different. The functions of the buildings are also different. Some produce resources, some increase the efficiency of other buildings, some even affect completely different game entities.
And the task of a game designer is to build work with data in such a way that they are understandable to colleagues, are pulled up by the engine and are changeable.
How to do it?
Step by step.
1. Approval of the data format
The first step is to agree with programmers on the format for transmitting content information to the engine.
There are many ways to solve this issue.
For example, we could use the ScriptableObject mechanism or register data in scripts directly in Unity/UE. However, this option would be suitable only if the amount of content of a certain type would be small (for example, if we were talking about three or five buildings) or if we were dealing with a unique object on the stage at all.
So if there are ten lines of data in your game, you don’t need any “Google Tables“, JSON and other solutions.
In our case, there can be up to a hundred buildings. Each imposes one or another effect on the planet, the territory around, neighboring buildings, affects the production of resources. Also, everyone has many levels of development.
You can’t write all this in the code. Plus, in this case, there will not be the flexibility we need. Deleting, adding, balancing content will not just be inconvenient, but problematic.
And this is true for any game where hundreds of configuration files need to be filled in to describe the content, and editing in the balance of one unit of the game affects dozens of different tables.
Therefore, I recommend using JSON or XML scripting markup languages as the format for transmitting information (the old Lua and the more advanced YAML are also suitable).
For a specific project, I settled on JSON.
Someone notes its advantages in the usual syntax that came from JavaScript. I think the main advantage is the availability of ready—made free modules in asset stores for serialization of data from JSON / XML.
Plus, the experience of my students shows that learning to write in JSON is a matter of a few days. It’s not the same as learning an engine or a programming language.
So, we have agreed with the programmers on the format of information transmission. After that, the game designer must generate a complete list of parameters for each type of objects, indicating the data type and possible limits.

Figure 1. A fragment of the Confluence page with a list of parameters of a JSON script describing the scenarios
The resulting list must be agreed with the programmers. They will turn the document created by the game designer into a description of the data structure in the game code.
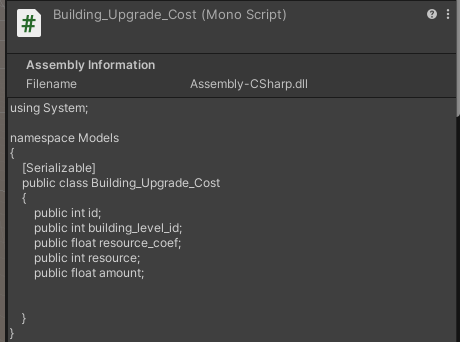
Fig. 2. Screenshot of the description of the data structure of the JSON config of the cost of improving buildings in Unity
2. Connections and data structure
As a rule, there are no isolated objects in games. Each object is interconnected with some data.
To fix these relationships and form a data structure, it is convenient to use SQL terminology, and also consider each list of content of a certain type (in our case, buildings) as a table.
Keys and communication types
When forming a data structure, it is important to remember the following concepts:
Foreign keys
Identifiers (usually in the form of natural numbers) by which objects from some tables can receive information from others.
Types of links
The logic of using internal and external keys. Usually allocate:
- One-to-one: A relationship between information from two tables when each record is used in each table only once. For example, the identifier of a building in one table fully corresponds to the same identifier in another.
- One to many: in this kind of relationship, a row in Table A can have many rows in Table B. But a row in Table B can have only one row in Table A. For example, one building corresponds to many upgrade levels, at each of which it can have different properties.
- Many to many: a relationship in which multiple records from one table (A) can correspond to multiple records from another (B). For example, the “Four-Dimensional Factory” building on the fifth level opens an additional construction slot in the area where it is located. And the “Heavenly Filatures” property also imposes an effect on the building, adding an additional construction slot to the zone.
If there is a technical possibility, try to create effects and other fields with unique ids, giving preference to the one-to-many relationship.
The normal form of a database is a set of rules that assumes that data redundancy is avoided. There are several of them, there is quite a lot of information about this on the web.
The formation of the data structure of the project configuration files is easier to show by example. Let’s take a brief look at the mechanics of building construction.
- The player’s planet is divided into zones, each of which consists of hexes.
- One building can be located in one hex.
- In addition to buildings, there may be sources and anomalies in the zone.
Sources are a blank for a building. For example, a quartz deposit will allow you to build only one specific building in this cell, which will extract stone.
An anomaly is a virtual container containing effects that begin to work after its investigation, and/or resources that can be taken away after investigating the anomaly.
Buildings can have a different number of levels. Each level has:
- the price you need to pay to improve the building to this level;
- a set of effects that gives the building at this level;
- resources that are produced at this level.
One building can have several second levels. This means that when the building is upgraded to the second level, the player chooses exactly how to improve the structure.
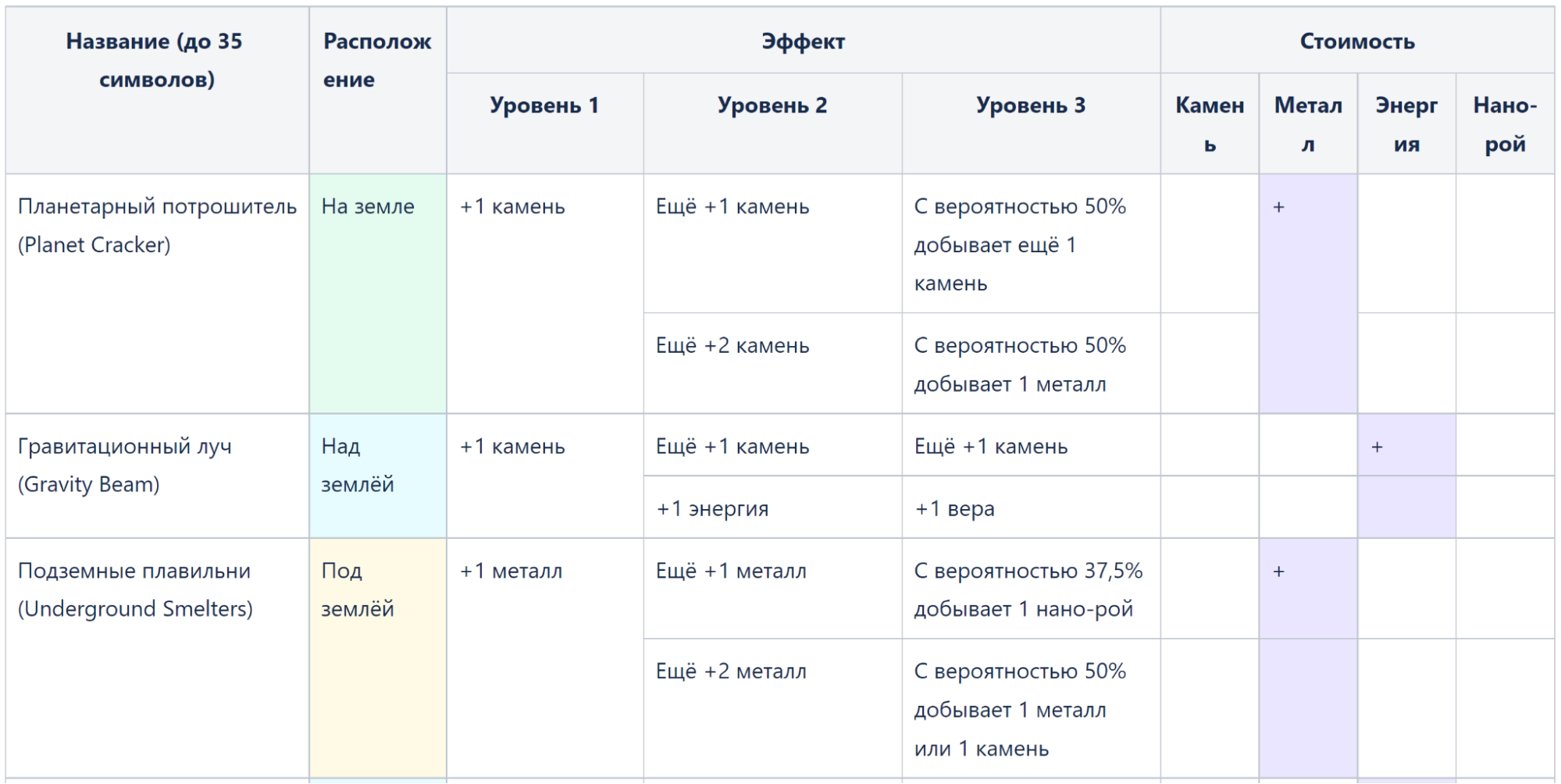
Fig. 3. Fragment of the Confluence page with a description of the development of buildings
As you can see in the screenshot, the “Planetary Ripper” building (yes, I’m a fan of Dead Space) requires metal for construction. Once built, it starts producing 1 stone per turn. The player has the opportunity to improve it twice. When improving to the second level, the player chooses one of two options: to increase the extraction of the stone by 1 more or by 2 at once.
The second option will cost the player more by 100% + 30% (the inflation rate of upgrades). When the building is upgraded to the third level, the building not only produces stone, but also gets a special effect to choose from: an additional 1 metal or 1 stone per turn with a 50% probability.
Let’s design a data model that would allow us to describe such building development opportunities.

Fig. 4. Relationships between content lists (tables) in the configs of buildings
The main table of the current model is Buildings. It describes all the buildings available in the game. Each of them is assigned a unique numerical number — id (natural number). By this number we will identify the building in all tables.
Let’s say we need to get a text description or asset (for example, a 3D model) of a specific building. In this case, the program code runs through the Buildings table and finds an occurrence with the specified unique id in it. Then he takes the necessary information from this occurrence.
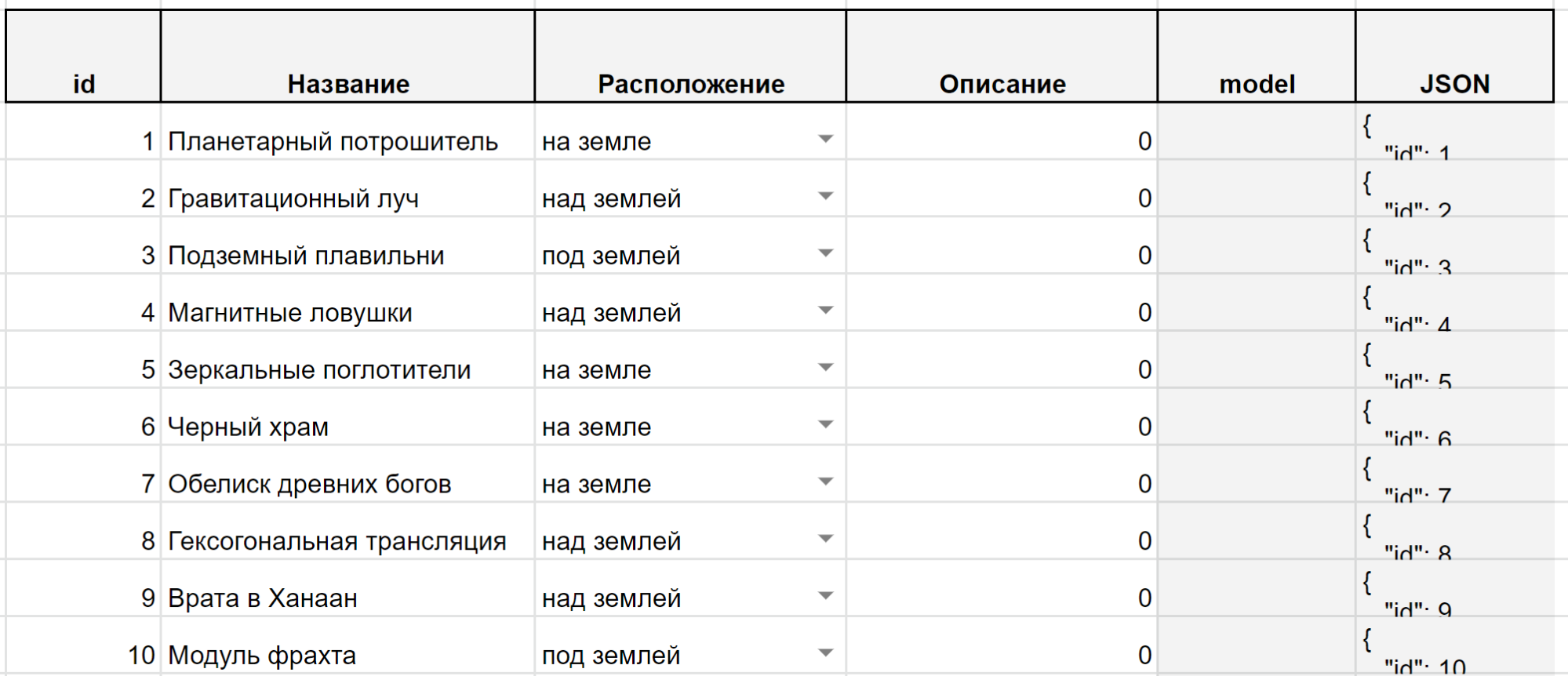
Figure 5. Screenshot of Google Tables with a fragment of the content of the Buildings table
In addition to the Buildings table, there is a Building_Levels table. It contains a list of all levels of all buildings. In particular, there will be five occurrences for the Planetary Ripper building: one for the first level of construction and two for the second and third levels. All these occurrences will have a different id, but the same building_id. It is a foreign key by which you can uniquely find a building from the Buildings list.
This data structure allows the product to have a different number of levels with different bonuses for each building. Game designers will be able to design source buildings that will simply extract resources and improve ten times. Or complex space ports that can be improved only a couple of times, but in five different ways. This is a demonstration of the work of one-to-many communication.
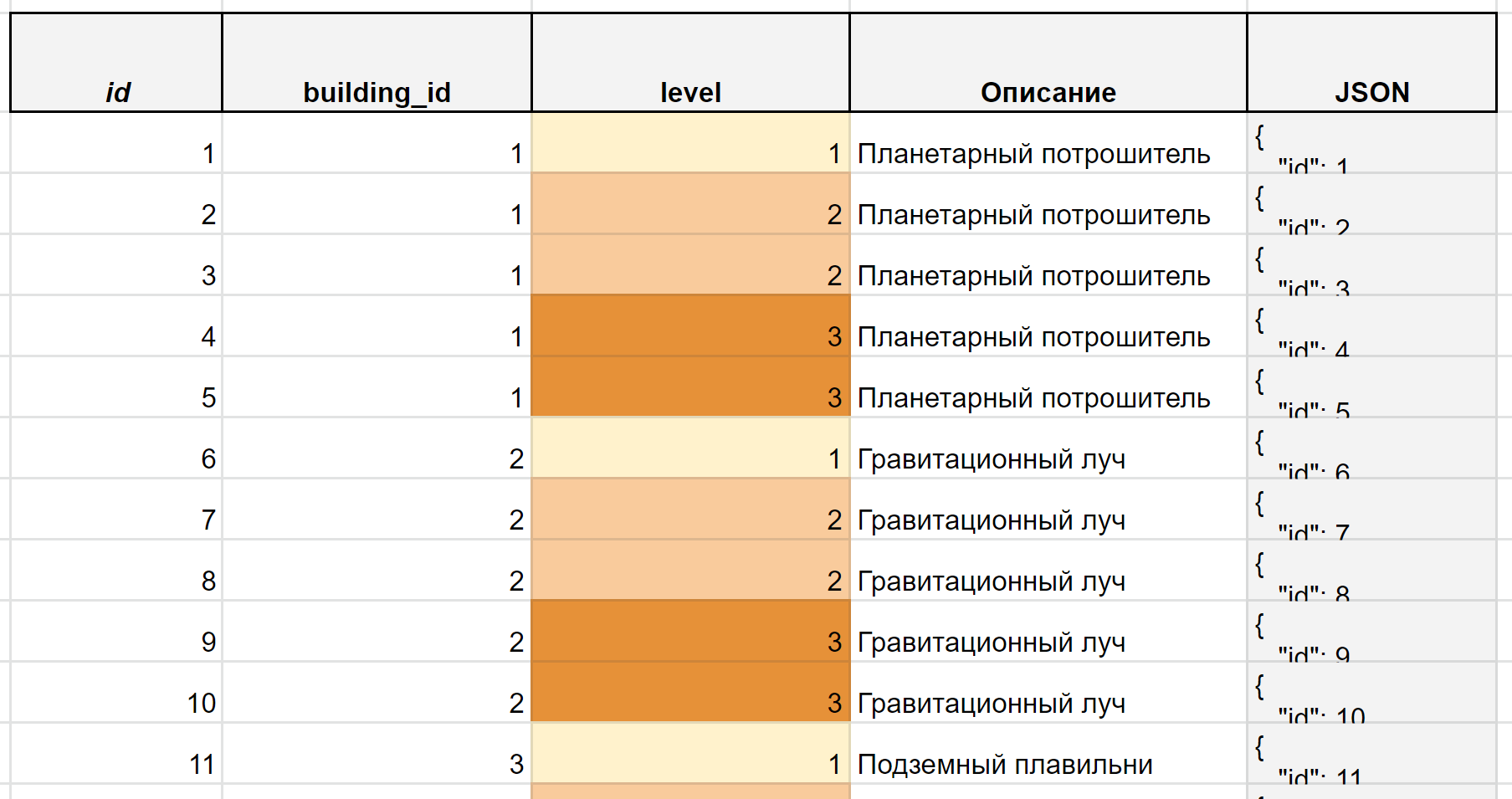
Fig. 6. Screenshot of Google Tables with a fragment of the content of the Building_Levels table
Upgrading a building to a new level and choosing one of the options for such improvements may have different costs. It is logical that the expansion of production by +3 should cost more than the expansion by +1. Otherwise, we will make a mistake called the imbalance of “uselessness or hyper-usefulness” according to Garfield: why buy something for an expensive price that is worse than a cheaper analogue.
To design a different cost of improvement to each of the level options, it is convenient to enter an additional Building_Upgrade_Costs table. Its structure is similar to a table of levels. However, now the foreign key referenced by the occurrences in this table is no longer buildings, but specific levels. For each such level, there is a list of resources that must be given for the upgrade.
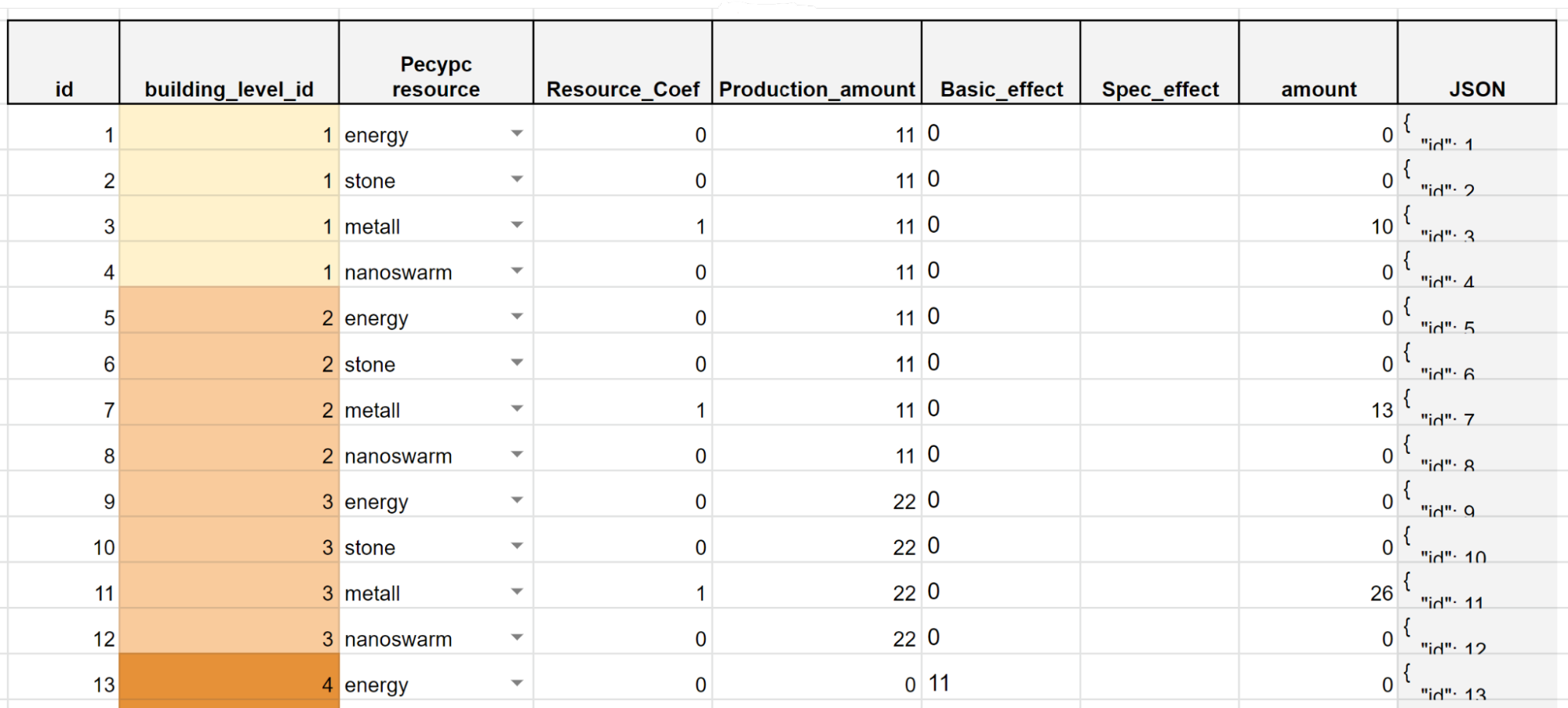
Fig. 7. Screenshot of Google Tables with a fragment of the content of the Building_Upgrade_Costs table
Similarly, the Building_Effects and Building_Production tables are described, which are responsible for special effects of the type “With a 50% probability produces 1 metal or 1 stone” and for the amount of resources produced, respectively.
3. Pipeline of content generation
The main scene of the game is a planet, on the hexa of which the player places buildings by dragging the corresponding cards there. Each turn he gets one card (a blank for building or a spell). From this brief description, the first steps to understanding the process are already being formed:
- Development of design documentation for game mechanics (construction and upgrade of buildings);
- Creating a list of building features:
a) Resource production. For example, +1 energy / stroke;
b) Random drop. For example, with a probability of 75% brings a unit of random resource each turn;
c) Modifiers (coefficients) of the economy. For example, +5% population growth rate;
d) Complex effects with selectors and conditions. For example, all the stone sources in the zone consume 1 less energy for each level of improvement. - Creating a list of content (buildings);
- Formation of the Excel/ Google (or other) table structure in which data will be recorded;
- Filling the table with content, and balancing it;
- Generating and verifying data in the project’s own format or in one of the generally accepted data transmission formats. For example, JSON, YAML, LUA…
- Transferring data to the engine and building the build;
- Testing the validity of data and game balance in the game.

Fig. 8. Screenshot of a fragment of the Confluence page with a description of the planet and the construction of buildings
The screenshot above shows that to describe the mechanics of construction alone, we have prepared several documents at once telling what a planet is, zones and hexes on it, how cards are played, with which buildings are created, how they are placed on the stage, and so on.
It is more convenient to divide a huge document into small articles that reveal individual elements of mechanics, connected into a single structure by a system of links that permeate the entire narrative. Fortunately, Confluence, Notion and similar services for maintaining project and product documentation are perfectly adapted for this.
Also, the separation of content and description of mechanics can be considered a good tone. It is not necessary to combine into one big article how buildings work, what kind of economy is behind them and the list of these buildings itself. However, this rule is not universal. It is a consequence of the simple convenience of information consumption. If your mechanics are limited and do not require hundreds of units, spells, levels, then it can be convenient to paint everything on one page.
4. Formation and filling of the content table
Having approved product documentation and content, the game designer comes close to the question of how to describe all this in technical language now.
To start working with buildings, you must first describe everything related to them: resources, cards, economy.
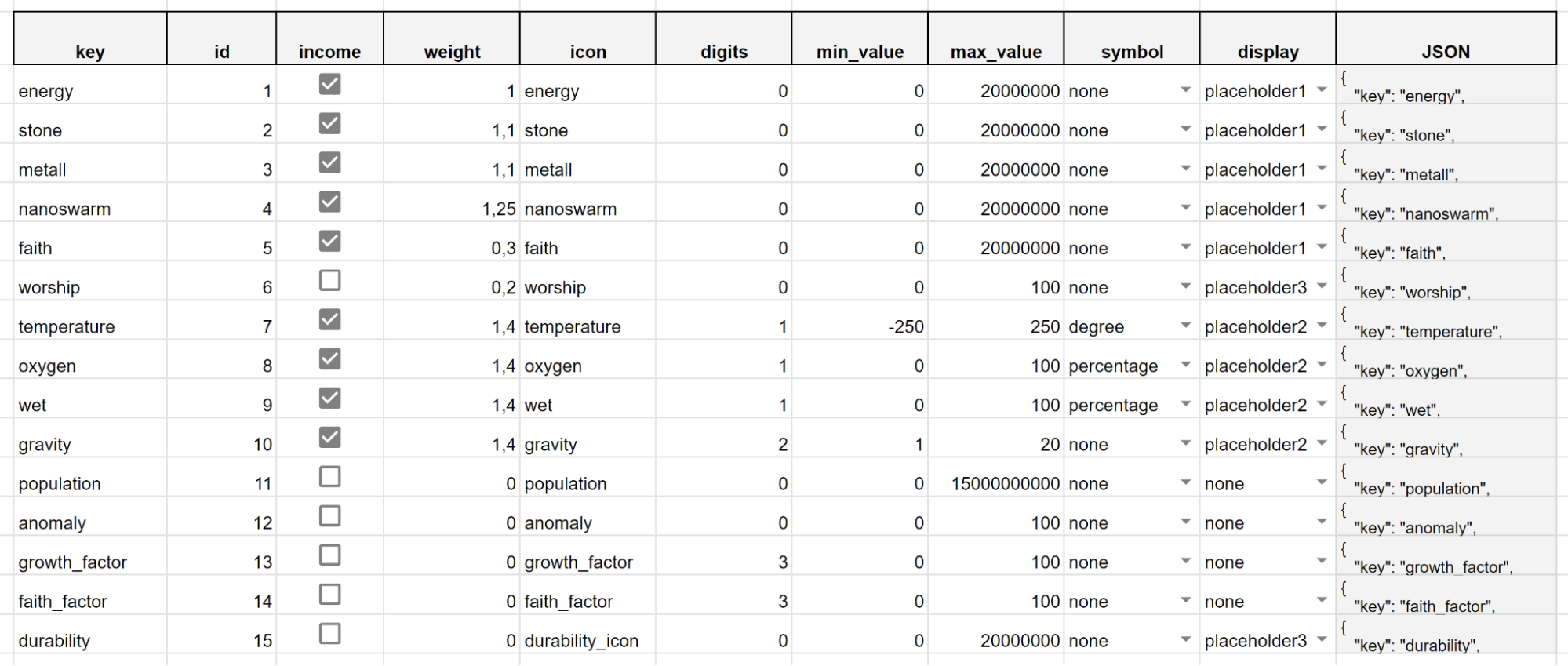
Fig. 9. Screenshot of the resource table in Google Tables
Note that in the table of buildings there is no information about what this or that building does, how much it costs to erect it and raise the level.
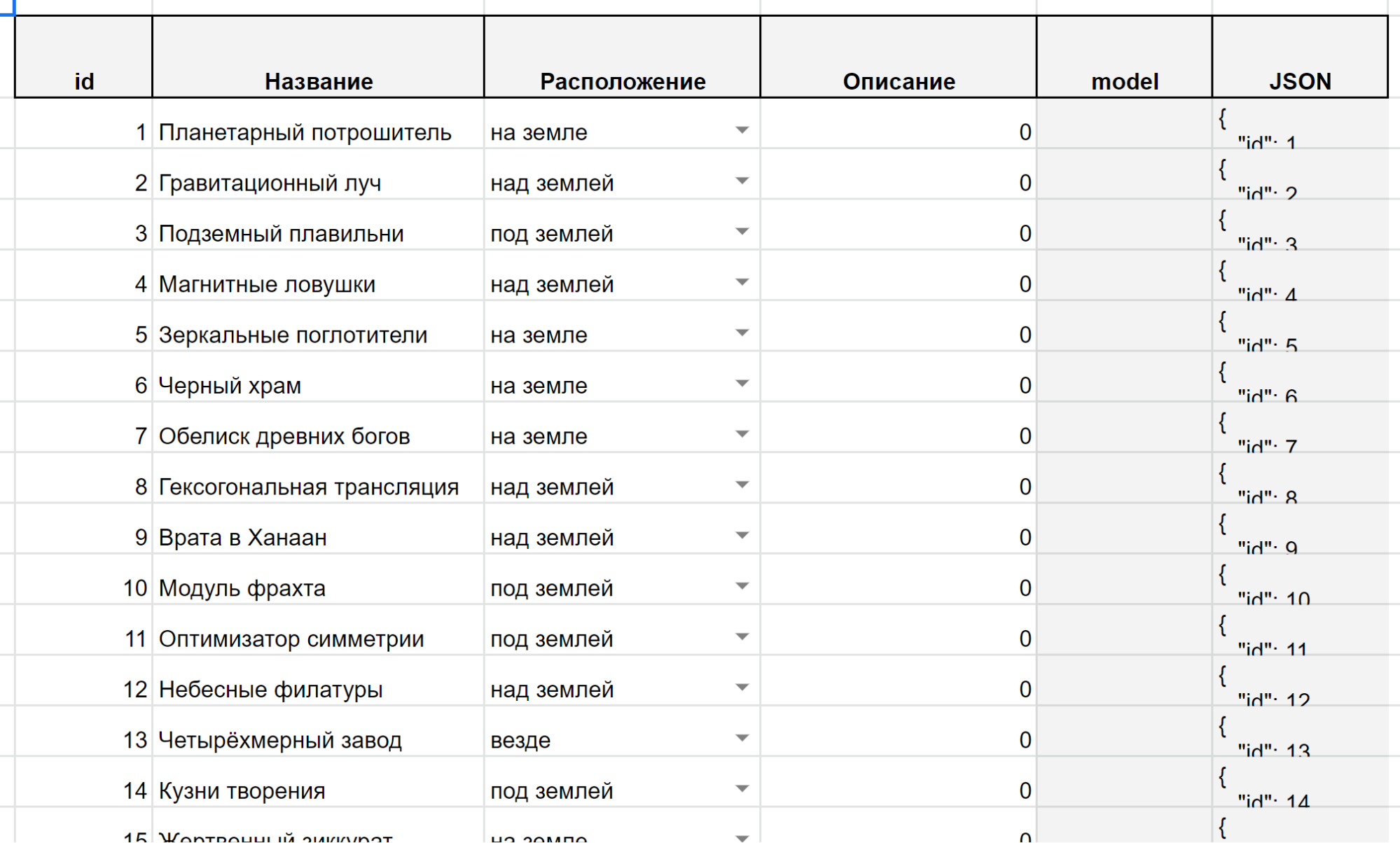
Fig. 10. Screenshot of the table of buildings in Google Tables
I note that the text in the “Name” field is used solely for the convenience of game designers, and the real texts of the artistic description, title and even description of the effects are placed in the localization file. The logic of its operation is based on the same principles as other tables.

Fig. 11. Screenshot of the localization file
By his example, by the way, it is convenient to dwell on the advantages of automation.
1. Automatic checks
“Google Tables” protect the game designer from incorrect content input. At least they warn you if incorrect data is entered. So, for example, when selecting a group to which the localized text belongs, the options suitable for this group are automatically loaded into the subgroups field.
For example, if we selected the “Planet” group, it will be impossible to specify a subgroup of keys that are not related to the planet. The same is true in all other tables: specifying the range of numbers that the resource value can take in the resource table (min_value, max_value), you can enter only a rational number from minus maxint to maxint. Entering a different text will cause an error, warning the game designer that the input data can only be a number. As a result, programmers will receive guaranteed verified and valid configs from game designers.
2. Highlighting of cells
This helps to understand what data has not been filled in yet. For example, in the screenshot with the localization file, we see that a blank for the next localization key is entered in the second line. We have chosen the “Planet” group, the “Building” subgroup, but have not yet described exactly which text will be recorded in this key. Therefore, the file highlights the “Item” field in red. In one of the lines below, the text in the “Item” field is filled in, but no translation has been entered, so the “ru” field is highlighted, standing after the “key” (localization key). Russian Russian is the original language of the game, then you can configure the table so that it highlights all the fields in English, Spanish and other languages for which the game designers have changed something in the Russian localization. This way we will never forget to retranslate a text whose original has changed.
An equally important part of content input automation is the balance calculation.
A normal situation is when game designers have to constantly add new content (in our case, buildings) and count production, purchase price, improvements and many other parameters from scratch. This is not only a waste of time, but also another place where you can make a mistake.
The general principle in all game projects I have worked on: automate everything and never write code yourself. Any manual work is a chance to make a mistake.
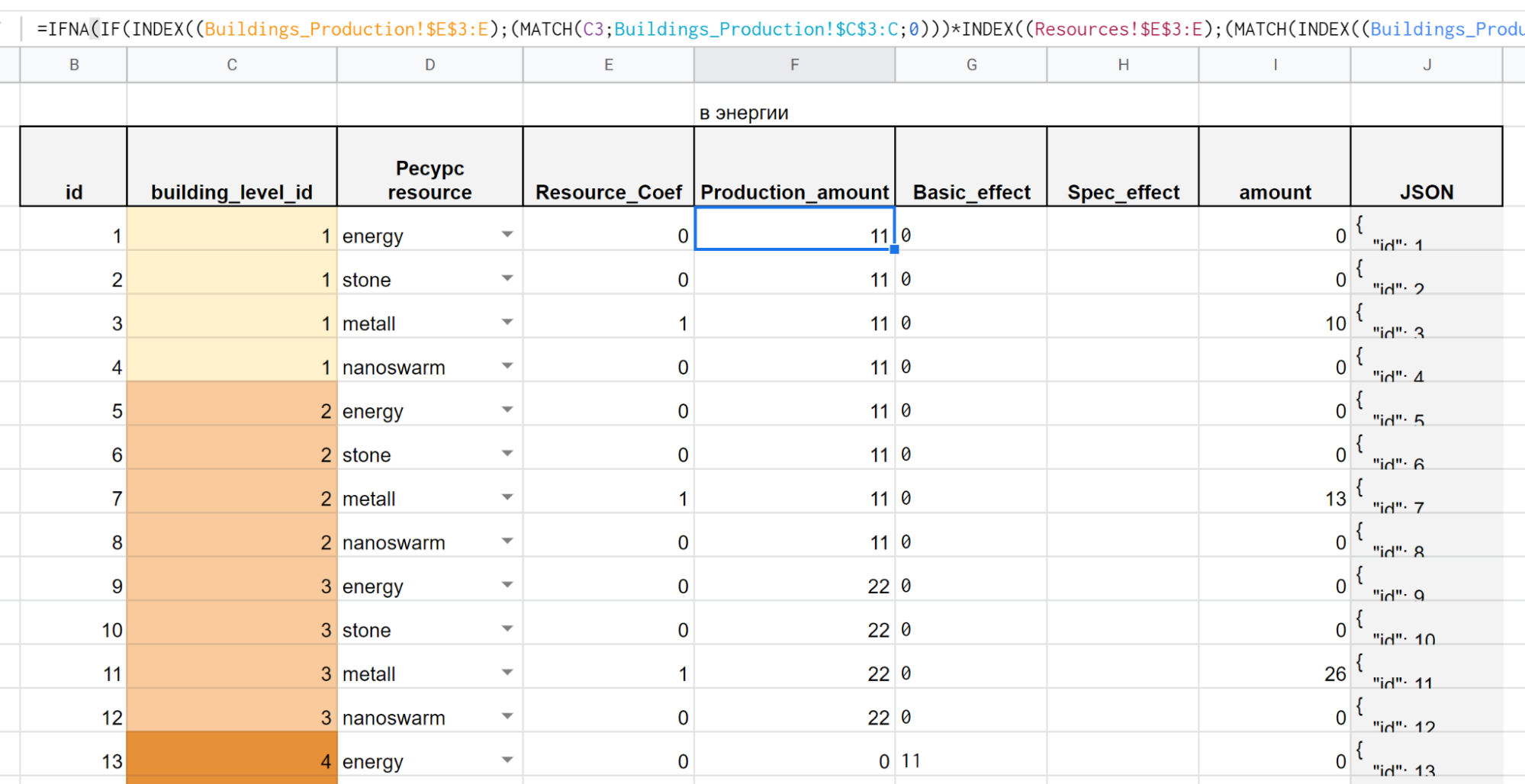
Fig. 12. Screenshot of the table of the cost of upgrading buildings to a given level
The screenshot above shows that some of the parameters are calculated automatically.
For example, we know that construction has no effects other than the simple production of resources. Then, let’s say the “Planetary Ripper” on the first level produces 1 stone per turn.
Our task is to calculate the cost of building this building.
Game designers decided that at the first level it would be built only of metal. So we need to calculate how much metal a building producing 1 stone will cost. To do this, we need to know two things:
- how do the values of metal and stone relate to each other;
- for how many moves the building should pay off.
The first parameter is set by the “weight” coefficient in the resource table (see Figure 9). The second is a constant fixed on a separate page.
Knowing all this, the table calculates the cost of construction in energy (the cheapest resource), and then translates it into a given resource — metal.
The table also takes into account a lot of other nuances and coefficients. For example, inflation with an increase in the level of construction or the number of buildings in the zone.
I specifically describe the process of balance superficially, since the story about it is material for a separate small three—hour lecture. Our current task is to understand and make sure that balance and mathematics can and should also be automated.
5. Validation and data transfer to the engine
The next step is to encode the information from the tables so that it can be passed to the engine.
As I have already written, we use the JSON format for this, but nothing prevents you from choosing any other way of presenting information.
Pay attention to any screenshot from Google Tables with configs (Fig. 9, , 10, 12). The last column always contains a cell for the JSON script.

Fig. 13. Screenshot of the JSON script generation formula

Fig. 14. Screenshot of the final JSON script generated by the formula
Each row with data eventually ends with a cell with a script containing the information written in the row.
The next step is to check that the script generated by the formula contains working code without errors. To do this, it is convenient to use various online validators. They are easy to find in the search engine for the query “JSON online validator”.
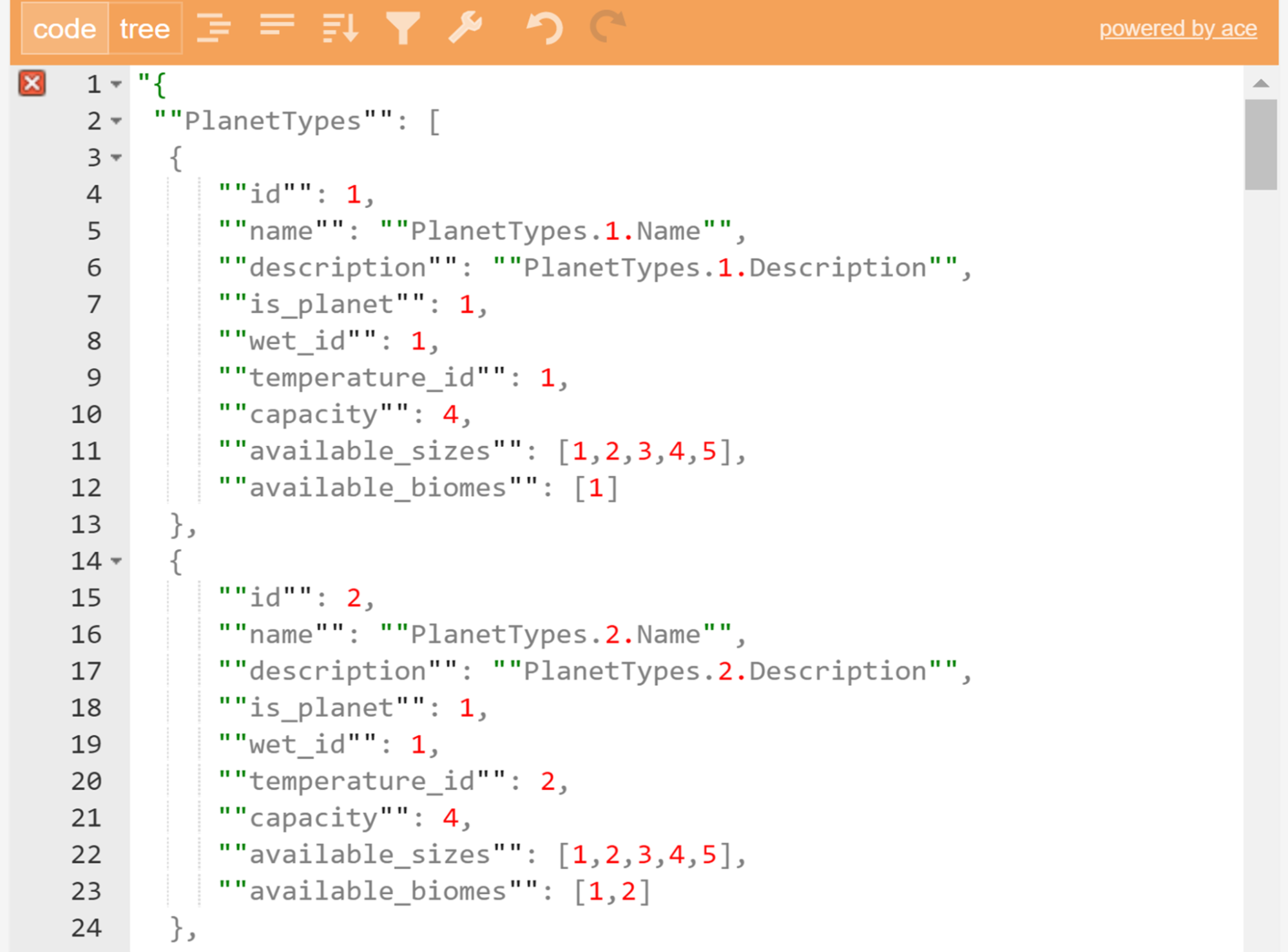
Fig. 15. Screenshot of the JSON code in an online parser that checks it for errors
After checking the data for errors, the script should combine the data from all rows into one cell, from which it will be convenient to copy the final text to the editor.
If you do not build the build manually, but use automatic assemblers, you can also add the ability to automatically pull text from a given cell, overwriting a particular configuration file.
The final algorithm for automating work with content can be briefly depicted in the diagram:
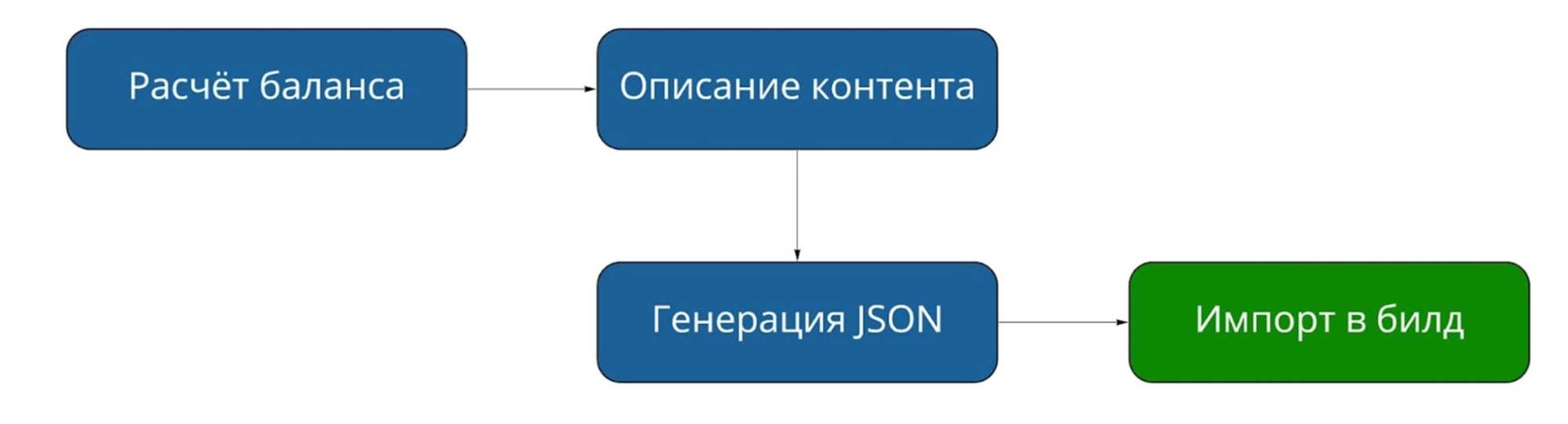
Fig. 16. The scheme of working with content
6. Instead of conclusions
Thank you for reading the material to the end. I hope he was helpful.
I know that reading technical texts with a large number of tables can be quite boring, but it is very important for the development of a production culture in the team.
It doesn’t matter whether your game is a big project with millions of budgets or a small adventure from an independent team, if you are aiming for commercial success, automation of the technical side of the development process is one of the most important elements of creating a game, without which the risk of production hell is much higher.