Legal issues of using AI when creating graphics. Analysis from i-Legal
Despite the rapid growth in popularity of AI services that generate visual content at the request of users, from a legal point of view, their work (as well as the use of graphics created by them) raises many questions. I-Legal lawyers answered the most relevant of them in a special material for App2Top.

Selection of images by searching for “midjourney” in Yandex
Authors: Natalia Yurkov a, Managing Partner of i-Legal, Alexey Kononov, Lead Lawyer of i-Legal, and Maria Ordovskaya-Tanaevskaya, Advisor to the Corporate Department of i-Legal.

Natalia Yurkova, Alexey Kononov and Maria Ordovskaya-Tanaevskaya
Am I a trembling creature or do I have the right to copyright
In 2022, it seems that everyone had time to look at the anime version of a pet in the Chinese neural network QQ or, thanks to Midjourney, to be transported to the world of Harry Potter with a bias in cyberpunk.
The images generated by neural networks quickly “swirled”, actually making us part of the training mechanism of generative artificial intelligence (generative artificial intelligence; Eng. generative – “generative”), which can not only analyze data, but also create them.
“What’s in the box?”
When today they talk about generative AI that converts text into content (text-to-content generation), namely, into images, they most often mean DALL–E 2 (developed by OpenAI; generates photorealistic images), Midjourney (developed by an independent laboratory of the same name; available via a bot in Discord; has its own, recognizable style and allows you to imitate the style of artists; there is a trial version, paid by default) or Stable Diffusion (the open source model of the Stability AI startup; available through the paid Dream Studio service, through third-party applications or as a free version on the user’s device).
Press “/imagine” to start
To generate content using a neural network, users enter text (the so–called prompt; from the English prompt – “hint”), and AI converts it into an image.
In prompta, you can specify fairly basic things: the subject, color, artistic style. And you can wind up parameters that require more narrowly focused knowledge by setting the focal length, introducing chromatic aberrations or making a reference to a specific “engine”, for example, Unreal Engine.
An example of a prompta and an image generated from it:
«a man in a long dusty black coat and a flat hat riding a walking black horse on a street amidst the ruins of a post-apocalyptic city riding towards the sunset on the horizon, bleak scenery, grim atmosphere, hyperreality, landscape photography, ultra-wide angle, depth of field, hyper-detailed, beautifully coloured, insane details, beautiful color graded, Shutter speed 1/1000, F/22, white balance, 4K, 8K, RTX rendered, super-resolution, lonely, fully colored, soft lighting, Chromatic Aberration – Variations by @9664989620 (fast)»

The image and prompta are taken from the Midjourney bot in Discord. Variations by @9664989620
Prompt is used for the most effective instruction of AI. By their design, prompta can be quite complex, while they are a set of individual words, albeit composed according to a certain principle. Therefore, unlike “tweets”, it is difficult to imagine that one prompta will be an independent object of copyright. However, the totality of such prompta, which can be compared with a database, under certain conditions could be granted legal protection.
As for the use of the name of the artist or character in the prompta as a reference, the very fact of mentioning in the text of the prompta, for example, the artist Leonid Afremov (whose style is quite recognizable), should not constitute a violation, but the final result of AI work obtained in this way can. Why? Let’s try to figure it out.
“Out of a hundred rabbits, a horse will never be made up, out of a hundred suspicions, evidence will never be made up”
Generative AI is trained to recognize patterns in the provided data and reproduce them. To train an AI that converts text into an image, visual material is required, which is the result of intellectual activity, as a rule, protected. In other words, using images from the Internet without the permission of the copyright holder is not always an acceptable practice.
At the moment, the possibility of “training” AI on copyrighted images is justified by the doctrine of fair use, common in the United States and in the United Kingdom, which, under certain circumstances, allows the use of works, in particular, copyrighted images, without the consent of the author.
When assessing whether fair use has taken place, the courts consider the following parameters (using the example of the US Copyright Act of 1976):
1. Purpose and nature of use (how the original work is used and whether the use is commercial)
In order for the use of data to be considered non-commercial, it is necessary that the training data and the model be created by researchers and non-profit organizations. Companies strive to meet this criterion: Stable Diffusion uses the LAION database (a German non-profit organization) under license, while the company itself did not collect data and did not train the model (thanks to this, Stable.AI has the ability to sell premium access to the model); DALL-E 2 is also developed by the non-profit organization OpenAI (Microsoft is a key partner and investor).
But the situations described above, which have been dubbed “AI data laundering“, already raise questions from the point of view of formal compliance with the criterion for preserving the possibility of applying the fair use doctrine. Therefore, it is quite difficult to determine unequivocally whether the courts will consider the use to be truly non-commercial.
2. The nature of the copyrighted work (to what extent the work itself relates to the purpose of copyright, which is to encourage creativity, whether it is creative or more factual in nature)
A study of data from more than 12 million images in LAION-5B (used for Stable Diffusion training) showed that 47% of images come from just 100 domains, such as Pinterest or DeviantArt. However, the very fact of the origin of the image from the site providing the license does not mean that such a domain is the original source of the image or that its use is permitted. For example, with the help of a tool that allows you to check whether there are works by certain artists in the data on which the training takes place, images previously deleted from the RedBubble store were found.
In addition, by indirect signs, it can be judged that AI studied the works of a certain artist. For example, Midjourney’s “response” to prompta with the words “Leonid Afremov” demonstrates that the network is familiar with him:
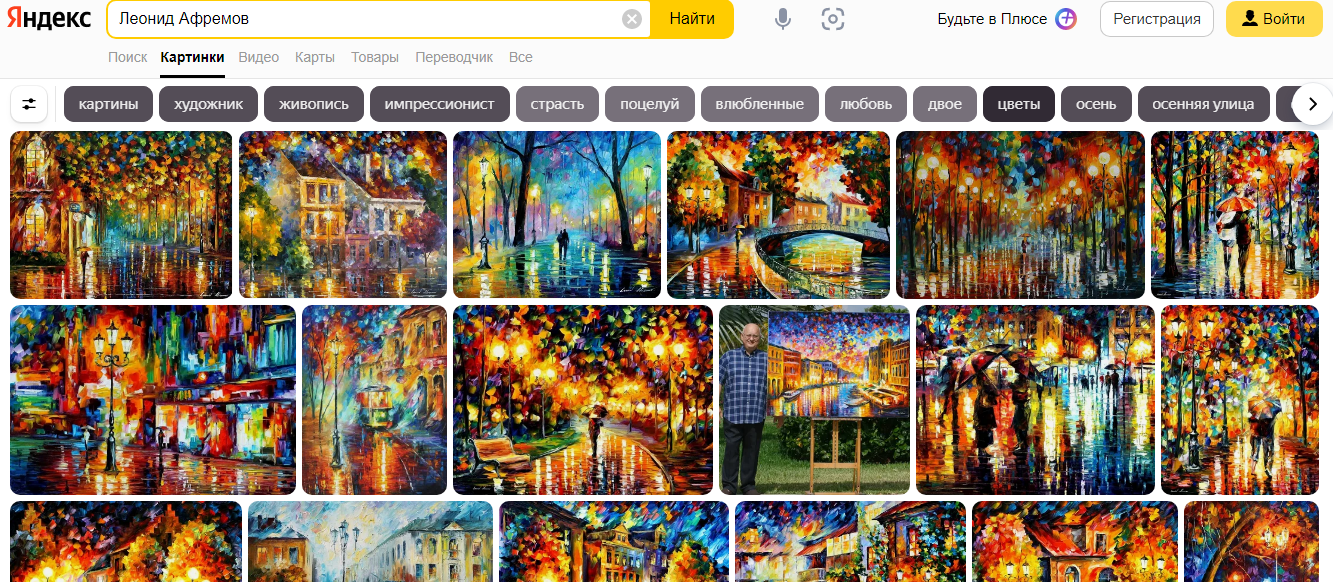
Selection of images for the search “Leonid Afremov” in Yandex

Generated Midjourney images by prompta with a mention of Leonid Afremov’s style
Thus, there is a high probability that, according to this criterion, the fact of using AI images protected by copyright will testify in favor of the authors of the original works.
3. The scope of use of the copyrighted work and its significance for the final result as a whole
The AI-generated images seem to be original and created for a specific prompta. However, a recent study conducted on the example of Stable Diffusion showed that it is technically possible to establish not only the fact that the received content is a “reproduction” in one or another part, sometimes significant, of images (English replication) on which training takes place and which AI uses to “train” its algorithms, but also and identify the original images themselves.
Compliance with this criterion is assessed individually in each case. It is difficult to predict whether the assessment will be technical in nature and based, as was done in the above study, on quantitative criteria, or more “subjective”, at the discretion of a person (how they perceive this or that image).
4. The impact that such use has on the value of the original work (whether and to what extent harm is done to the potential market for the distribution of the original work, for example, whether a replacement is being created for it)
This criterion is one of the most difficult and important for evaluating fair use. However, it is rather difficult to draw an analogy with the existing practice, if only because it is not completely clear whose actions the courts in practice can regard as capable of leading to what artists fear most of all – to the devaluation of their creativity and all those years that have gone into acquiring skills and forming their own style.
Should companies be blamed as the creators of this weapon of mass “intellectual and creative” defeat, or “ordinary users” who can turn this weapon erected on their own creations to the detriment of artists? Unfortunately, at the moment the answer to this question will lie more in the field of morality than law.
“Questions. Questions need answers”
If the probability that the fact of AI training on copyrighted images can be recognized as a violation of the fair use doctrine is quite small (since it fits into the above criteria), then the process of creating and further using content raises a large number of questions and requires the introduction of a more narrowly focused regulation that would give an answer, who and how has the right to use the resulting images.
While regulation in this area at the public level is limited by the technologies of their time, companies are making attempts to self-limit (or absolve themselves of possible responsibility), giving the user certain rights in their license agreements.
Thus, according to the Terms of Use of the Midjourney service, a user who does not purchase a paid subscription receives an international Commons Noncommercial 4.0 Attribution license. According to it, he can use the images by distribution, public demonstration, etc., but cannot use them for commercial purposes. In addition, the user cannot prohibit anyone else from using the works created by his prompta. In fact, Midjourney works as a shared workspace, and other people can use someone else’s prompta or generated images.
If the user chooses a paid tariff, then he becomes the full owner of images and other assets generated using the network. However, any images generated in an open source, for example, in a Discord chat, are available for viewing by third parties.
The user can purchase an additional privacy option (privacy add-on) to his subscription, and Midjourney undertakes to make every effort not to publish the works created by the user, that is, the user can create something like a private channel to generate his own works and use them commercially.
The creators of Midjourney also made a reservation with reference to the DMCA (US Copyright Law in the Digital Age) that the model uses an AI system trained on publicly available data to generate results. The output data may be unintentionally similar to copyrighted materials or trademarks, and the company is ready to consider requests related to potential violations.
In turn, Stable Diffusion is distributed under the Creative ML OpenRAI-M license, which allows users to:
- reproduce, publicly display, publicly perform, sublicense and distribute the model and any of its additional materials, for example, the source code and any derivatives of the model;
- using the model and any additional material commercially;
- retain rights to output data created by users using the model.
Stable Diffusion also stated that artists will have the opportunity to choose which works they want to exclude from the data used in training the Stable Diffusion 3 model. In turn, the artists believe that the authors should demonstrate explicit consent, and not “absence of objections”.
So, on ArtStation (a site for professional artists), a strike began against the use of AI-generated content. Now projects marked with NoAI (no AI) will be automatically assigned the HTML meta tag NoAI, prohibiting the use of such content by AI systems.
In accordance with ArtStation’s Terms of Service, all works posted on the site belong to artists, and ArtStation will not sell or license the works to other companies. In addition, the terms prohibit “collecting, aggregating, mining, deleting or otherwise using any content uploaded to the Site for the purpose of testing, entering or integrating such content with artificial intelligence or other algorithmic methods when such content has been marked or marked as NoAI by the content provider.”
Some authors express their disagreement in a more explicit way: for example, a lawsuit was filed in the Federal court of California (currently not considered) against Microsoft, GitHub and OpenAI. The lawsuit concerns the operation of the GitHub Copilot algorithm, which is jointly developed by OpenAI and GitHub (owned by Microsoft) and used under license by Microsoft.
In the process of writing the code, the algorithm suggests finishing the line, and a function has already been announced that will allow adding new, ready-made blocks to the code. According to the plaintiff, Copilot does not indicate authorship when reproducing open source code, the license terms of which directly require such indication. In addition, the lawsuit states that there was a violation of the DMCA prohibiting the removal of copyright information.
“And it goes out. And enters. It’s coming out great!”
The most important issue for both users and the networks themselves (from the point of view of the doctrine of fair use, in particular) will be the “generating” stage of the algorithm, when from the user’s prompta … whoosh! – and an image is generated.
It’s worth starting with the fact that another question awaits us here: which jurisdiction could be tied to in terms of regulation and the commission of a potential violation, taking into account the “distributed” AI network and the fact that the “violator” has not been fully established? Since no more is clear on this aspect than on the rest, unfortunately, it remains to rely only on publicly available sources of information, which at the moment contain the most references to the legislation of the United States and Great Britain, including as to the countries where the companies with which such networks are associated are located.
In the USA, works created exclusively by a machine are not protected by copyright. Legal protection may arise if it is proved that a person has made his own significant contribution. According to the US Copyright Office (USCO), based on the US Copyright Act of 1976, only a person can be the author of a work, and AI does not meet this requirement. So, Dr. Stephen Thaler, who applied for registration of a work of art created by AI, where he indicated himself as the copyright holder, and AI Creativity Machine as the author, received a refusal from the USCO, which he is currently trying to challenge (Stephen Thaler v. Perlmutter and The United States Copyright Office).
Therefore, the story attracts special attention when the image created by AI brought victory to its author, who presented the work “Théâtre D’opéra Spatial” at the contest after spending 80 hours creating 900 iterations and refining AI-generated images in Adobe Photoshop.
Also in the USA, the right to a comic book created with the help of Midjourney is registered as a work of fine art. The artist Kris Kashtanova placed on the cover a direct indication of how exactly the images were obtained.
The UK is one of the few countries that provide copyright protection for works created exclusively with the help of a computer. An author in the UK is considered to be “a person who takes the measures necessary to create a work.” It seems that this interpretation can be interpreted in various ways (will this “person” be the developer of the model or, for example, just its operator?).
As one of the ways of commercialization, AI-generated images can be placed on stock sites. However, there is no common position among the major players in this field about the permissibility of such images:
- Getty Images has banned images obtained using AI, pointing out that the sale of AI artwork could potentially expose users to legal risk;
- Shutterstock has made a deal with OpenAI to integrate DALL-E; at the same time, artists whose work was used to train models will receive a refund;
- DeviantArt announced that it would use users’ content to train AI, but after the subsequent outrage on their part, it reversed its decision;
- Adobe Stock recognizes content created using AI, but subject to certain rules, for example, the image name must include the “Generative AI” tag.
In Adobe’s Policies, the user is responsible for the content:
- “… you guarantee to us that you have all the rights for Adobe Stock to use the content… that the content does not violate any rights of third parties“;
- “Never submit content that violates the rights of third parties, including imitation or replication of content or style“;
- “Don‘t use an image you don’t have rights to as a parameter for your generative hints for AI.”
“Annushka has already bought sunflower oil, and not only bought it, but even spilled it”
The learning process of generative AI cannot be reversed, forcing the network to forget Leonid Afremov’s paintings as if by a flash of the neuralizer of the men in black. You can either destroy the model (which already seems unlikely given the spread of Stable Diffusion as an open source project), or take appropriate regulation.
Unfortunately, the speed of implementation of such regulation does not correspond to the pace of AI development, and the most difficult issues lie not in the field of copyright, but in much more subtle matters for application: ethics and morality.
If you want to create, post or use materials obtained using AI, in the conditions of current regulation, or rather, its absence, you can only recommend carefully studying the current conditions of services, consult with lawyers and be mentally prepared for unexpected “plot” turns in this area that is gaining cosmic speed of development.